CubeWerx Inc. |
Publication Date: 2022-05-30 |
External identifier of this CubeWerx® document: https://cubewerx.pvretano.com/Projects/CSA/doc/csa.html |
Internal reference number of this CubeWerx® document: 22-001 |
Version: 1.0 |
Category: CubeWerx® Design Document |
Editor: Panagiotis (Peter) A. Vretanos |
CubeWerx TEP Marketplace Design Document |
Copyright notice |
Copyright © 2022 CubeWerx Inc. |
To obtain additional rights of use, visit http://www.cubewerx.com/legal/ |
Warning |
Document type: CubeWerx® Inc. <Design Document> |
Document language: English |
CubeWerx proprietary and confidential disclaimer
The information contained in this document is intended only for the person or entity to which it is addressed. This document contains confidential and intellectual property of CubeWerx. Any review, retransmission, dissimination or other use of, or taking of any action in reliance upon this information by persons or entities other then the intended recipient is strictly prohibited without the express consent of CubeWerx. If you receive any content of this document by error, please contact CubeWerx and delete the material from all your computers.
- 1. Scope
- 2. References
- 3. Terms and Definitions
- 4. Conventions
- 5. Scenarios
- 6. Requirements summary
- 6.1. Overview
- 6.2. Web front end
- 6.3. Authentication & Access Control
- 6.4. User Workspace Management
- 6.5. Job manager
- 6.6. License manager
- 6.7. Notification and analytics
- 6.8. Execution and Management service
- 6.9. Catalogue
- 6.10. Application execution (ADES)
- 6.11. Cost estimation and billing (ADES)
- 6.12. Parallel execution module (ADES)
- 6.13. Results manager (ADES)
- 6.14. Storage layer
- 6.15. Federation
- 6.16. Administration
- 7. System Architecture Overview
- 7.1. Web front end
- 7.2. Execution Management Service (EMS)
- 7.3. Authentication server
- 7.4. User workspace manager
- 7.5. Job manager
- 7.6. License manager
- 7.7. The Notification & Analytics module
- 7.8. Application Deployment and Execution Service (ADES)
- 7.9. Catalogue service
- 7.10. Docker registry
- 7.11. Elastic Kubernetes Service (EKS) Container Execution Service
- 7.12. Storage layer
- 8. Security and Access Control
- 9. Workspace manager
- 10. Catalogue service
- 11. Jobs manager
- 12. License manager
- 13. Notification module
- 13.1. Event types
- 13.1.1. The user has reached 75% of their workspace size quota
- 13.1.2. The user has reached 90% of their workspace size quota
- 13.1.3. The user has exceeded their workspace size quota
- 13.1.4. A job has completed and processing results are ready
- 13.1.5. A job (i.e., process execution) has failed
- 13.1.6. An application/process has been added to the TEP Marketplace
- 13.1.7. An application/process has been updated in the TEP Marketplace
- 13.1.8. An application/process has been removed from the TEP Marketplace
- 13.1.9. A data set has been added as a TEP-holding
- 13.1.10. A TEP-holding data set has been updated
- 13.1.11. A data set has been removed as a TEP-holding
- 13.1.12. A new TEP-holdings web service is available
- 13.1.13. The data set served by a TEP-holdings web service has been updated
- 13.1.14. A TEP-holdings web service is no longer available
- 13.1.15. Another TEP user has shared a new web service with the user
- 13.1.16. The data set served by a shared web service has been updated
- 13.1.17. Another TEP user has stopped sharing a web service with the user
- 13.2. Notification methods
- 13.3. Database tables
- 13.4. Event Occurrences
- 13.5. Notification Daemon
- 13.1. Event types
- 14. Atom feed
- 15. Analytics module
- 16. Workflows and chaining
- 17. The OGC Application Package
- 18. Execution Management Service (EMS)
- 19. Application Deployment and Execution Service (ADES)
- 20. Quotation and billing
- 21. TEP Marketplace Web Client
- 22. Storage layer
- Annex A: Revision History
- Annex B: Bibliography
i. Abstract
The traditional approach for exploiting data is:
-
User develops one or more applications to process data.
-
The data of interest is copied to the user’s environment.
-
The data is processes in the user’s environment.
-
If the data is too voluminous, the data is segmented into smaller chuncks each of which is copied to the user’s environment for processing.
This results in the data being transferred many times and replicated in many places which in-turn introduces issues of scalability and currency of the data.
The exploitation platform (EP) concept endeavours to turn this traditional approach on its head. The fundamental principal of the EP concept is to move the user’s application to the data.
As opposed to downloading, replicating, and exploiting data in their local environment, in the EP approach users access a platform. The platform provides a collaborative, virtual work environment that offers:
-
Relevant data; in many cases the data is centred around a theme (e.g. forestry, hydrology, geohazards, etc.) and so the term "thematic exploitation platform" is introduced.
-
An application repository or "app store" (Software as a Service, SaaS) providing access to relevant advanced processing applications (e.g. SAR processors, imagery toolboxes)
-
The ability for users to upload their own applications (and data) to the platform.
-
Scalable network, computing resources and hosted processing (Infrastructure as a Service - IaaS)
-
A platform environment (Platform as a Service - PaaS), that allows users to:
-
to discover the resources offered by the platform
-
integrate, test, run, and manage applications without the complexity of building and maintaining their own infrastructure
-
provides access to standard platform services and functions such as:
-
collaborative tools
-
data mining and visualization applications
-
relevant development tools (such as Python, IDL etc.)
-
communication tools (e.g. social network)
-
documentation
-
-
accounting and reporting tools to manage resource utilization.
-
The CubeWerx TEP, the design of which is described in this document, is implemented according to the following principles:
-
Implement standards – to ensure interoperability
-
Implement infrastructure independence – to ensure cost effective infrastructure sourcing, avoid vendor lock-in, and allow reuse of public and commercially available information and communications technology
-
Implement pay-per-use – to avoid capital investment, contain costs, and allow for cost-sharing
ii. Keywords
The following are keywords to be used by search engines and document catalogues.
ADES, application, exploitation, EMS, marketplace, OGC API, platform, thematic, TEP,
iii. Preface
Attention is drawn to the possibility that some of the elements of this document may be the subject of patent rights. CubeWerx Inc. shall not be held responsible for identifying any or all such patent rights.
Recipients of this document are requested to submit, with their comments, notification of any relevant patent claims or other intellectual property rights of which they may be aware that might be infringed by any implementation of the system design set forth in this document, and to provide supporting documentation.
iv. Security Considerations
A Web API is a powerful tool for sharing information and the analysis of resources. It also provides many avenues for unscrupulous users to attack those resources. A valuable resource is the Common Weakness Enumeration (CWE) registry at http://cwe.mitre.org/data/index.html. The CWE is organized around three views; Research, Architectural, and Development.
-
Research: facilitates research into weaknesses and can be leveraged to systematically identify theoretical gaps within CWE.
-
Architectural: organizes weaknesses according to common architectural security tactics. It is intended to assist architects in identifying potential mistakes that can be made when designing software.
-
Development: organizes weaknesses around concepts that are frequently used or encountered in software development.
CubeWerx Inc. has primarily focused on the Architectural and Development views as those most directly relate to the design and implementation of the TEP Marketplace.
Development view vulnerabilities primarily deal with the details of software design and implementation.
Architectural view vulnerabilities primarily deal with the design of an API. However, there are critical vulnerabilities described in the Development view which are also relevant to API design. Vulnerabilities described under the following categories are particularly important:
-
Pathname Traversal and Equivalence Errors,
-
Channel and Path Errors, and
-
Web Problems.
Many of the vulnerabilities described in the CWE are introduced through the HTTP protocol which addresses many of these vulnerabilities in the "Security Considerations" sections of the IETF RFCs 7230 to 7235.
The following sections describe some of the most serious vulnerabilities which CubeWerx has endeavoured to mitigate. These are high-level generalizations of the more detailed vulnerabilities described in the CWE.
Multiple Access Routes
The TEP Marketplace APIs deliver a representation of a resource. The APIs can deliver multiple representations (formats) of the same resource. An attacker may find that information which is prohibited in one representation can be accessed through another. CubeWerx has taken care that the access controls on resources are implemented consistently across all representations. That does not mean that they have to be the same. For example, consider the following.
HTML vs. GeoTIFF – The HTML representation may consist of a text description of the resource accompanied by a thumbnail image. This has less information than the GeoTIFF representation and may be subject to more liberal access policies.
Data Centric Security – techniques to embed access controls into the representation itself. A GeoTIFF with Data Centric Security would have more liberal access policies than a GeoTIFF without.
Bottom Line: CubeWerx has taken care to ensure that the information content of the resources exposed by the TEP Marketplace API are protected to the same level across all access routes.
Multiple Servers
The implementation of an API may span a number of servers. Each server is an entry point into the API. Without careful management, information which is not accessible though one server may be accessible through another.
Bottom Line: CubeWerx has taken care to ensure that information is properly protected along all access paths.
Path Manipulation on GET
RFC-2626 section 15.2 states “If an HTTP server translates HTTP URIs directly into file system calls, the server MUST take special care not to serve files that were not intended to be delivered to HTTP clients.” The threat is that an attacker could use the HTTP path to access sensitive data, such as password files, which could be used to further subvert the server.
Bottom Line: CubeWerx has taken care to validate all GET URLs to make sure they are not trying to access resources they should not have access to.
Path Manipulation on PUT and POST
A transaction operation adds new or updates existing resources on the API. This capability provides a whole new set of tools to an attacker.
Many of the resources exposed though an OGC API include hyperlinks to other resources. API clients follow these hyperlinks to access new resources or alternate representations of a resource. Once a client authenticates to an API, they tend to trust the data returned by that API. However, a resource posted by an attacker could contain hyperlinks which contain an attack. For example, the link to an alternate representation could require the client to re-authenticate prior to passing them on to the original destination. The client sees the representation they asked for and the attacker collects the clients’ authentication credentials.
Bottom Line: CubeWerx has taken care to ensure that transaction operations are validated and that updates do not contain any malignant content prior to exposing it through the TEP Marketplace API.
1. Scope
This document describe the design of the CubeWerx TEP Marketplace. The document contains the following sections:
-
Scenarios: Describe the primary user scenarios that the TEP must satisfy.
-
Summary of requirements: Presents a summary of the requirements for the TEP marketplace.
-
System architecture overview: Presents the architecture of the system and describes the component of the system.
-
Security and access control: Describes the authentication and access control module. As the name suggested this modules allows TEP users to log onto the system and use resource offered by the TEP.
-
Workspace manager: Describes the workspace module which implement a virtual work environment for TEP users. All the resources a TEP user owns or has access to are encapsulated within their workspace.
-
Catalogue: Describes the catalogue of the TEP. The TEP catalogue contains metadata about all the resources of the TEP and the associations between those resources. The catalogue offers a search API to make those resources discoverable.
-
Jobs manager: Describes the jobs module which defines an API for managing jobs that are implicitly created whenever any processing is performed on the TEP. The API allows users to get a list of jobs, the status of a specific jobs and the results of processing once a job has completed.
-
License manager: Every resource offered by the TEP is subject to license requirements. The license manager is responsible to keeps track of all the licenses and enforcing license requirements whenever a TEP resource is accessed.
-
Notification and analytics module: Describes how users can subscribe to receive notification of events of interest that occur on the TEP. The TEP maintains an event log which is the basis of a subscription and notification system. The event log is also the primary data source for the analytics tools offered by the TEP.
-
OGC Application Package: Describes how an application package is used to deploy application to the TEP. An application package is a JSON document that defines the inputs and output of an application, specifies the execution unit of the application and includes metadata about the resource requirements to run the application.
-
Workflows and chaining: Describes how applications deployed on the TEP can be assembled into a larger sequence of tasks that process a set of data. Workflows can be executed in an ad-hoc manner or be parameterized and deployed to the TEP as new processes.
-
Execution Management Service: Describes the EMS which is the central hub of the TEP. The EMS interacts with and coordinates the operation of all the other components of the TEP to perform the functions of the TEP.
-
Application Deployment and Execution Service: Describes the ADES which is responsible for running the execution unit of a TEP process using the resources of the underlying cloud computing environment. The ADES is also responsible for making the results of processing available to the entity executing a process.
-
Quotation and billing: Describes how a user can get a cost estimate for executing a process on the TEP for a specific set of inputs. Once an application has been executed, this module is responsible for billing the costs of the run to the initiating TEP account.
-
TEP Marketplace Web Client: Describes the web front end of the TEP.
-
Parallel execution manager: Describes how the ADES analyzes and execute request to determine the extent to which that execution can be parallelized.
-
Results manager: Describes how the ADES make processing results available to the initiating entity.
-
Storage layer: Describe how data, TEP thematic data, user data and processing results are stored in the TEP. This is via a combination of database, file system storage and cloud object or block storage (e.g. S3).
2. References
The following normative documents are referenced in this document.
3. Terms and Definitions
3.1. Acronyms
ADES - Application Deployment and Execution Service
AMC - Application Management Client
API - Application Programming Interface
APP - User-define application
COTS - Commercial Off The Shelf
CRUD - Create, Replace, Update, Delete
EMS - Execution Management Service
IdP - Identity Provider
MOAW - Modular OGC API Workflows
OAProc - OGC API Processes API
OGC - Open Geospatial Consortium
STS - Security Token Service
TEP - Thematic Exploitation Platform
3.2. Terms
- area of interest
-
An Area of Interest is a geographic area that is significant to a user.
- application package
-
A Context Document is a document describing the set of services and their configuration, and ancillary information (area of interest etc.) that defines the information representation of a common operating picture.
- Dockerfile
-
A text document that contains all the commands a user could call on the command line to assemble a software image.
- container
-
A lightweight and configurable virtual machine with a simulated version of an operating system and its hardware, which allow software developers to share their computational environments.
- CRUD
-
An acronym for Create, Replace, Update and Delete which are the data manipulation operations supported by RESTful APIs using the POST, PUT, PATCH and DELETE methods defined in HTTP.
- infrastructure as a service (IaaS)
-
A standardized, highly automated offering, where compute resources, complemented by storage and networking capabilities are owned and hosted by a service provider and offered to customers on-demand. Customers are typically able to self-provision this infrastructure, using a Web-based graphical user interface that serves as an IT operations management console for the overall environment. Application Programming Interface (API) access to the infrastructure may also be offered as an option.
- resource
-
A resource is a configured set of information that is uniquely identifiable to a user. Can be realized as in-line content or by one or more configured web services.
- TEP-holdings
-
The primary dataset(s) offered by the TEP. For example RCM data or Sentinel-1 iamgery products.
- user’s TEP workspace data
-
Uploaded data and processing results generated by the user and stored in their workspace.
- virtual machine image
-
A virtual machine image is a template for creating new instances. An image can be plain operating systems or can have software installed on them, such as databases, application servers, or other applications.
- workspace
-
A virtual environment that manages all the resources and assets owned by a specific user.
- thematic exploitation platform (TEP)
-
A "Thematic Exploitation Platform" refers to an environment providing a user community interested in a common Theme with a set of services such as very fast access to (i) large volume of data (EO/non-space data), (ii) computing resources (iii) processing software (e.g. toolboxes, retrieval baselines, visualization routines), and (iv) general platform capabilities (e.g. user management and access control, accounting, information portal, collaborative tools, social networks etc.). The platforms thus provide a complete work environment for its' users, enabling them to effectively perform data-intensive research and data exploitation by running dedicated processing software close to the data.
5. Scenarios
5.1. App Developer Scenario
The app developer is a user who have created an application in their local environment and now want to deploy that application to the TEP marketplace. The following figure illustrates, at a high level, the basis steps taken by the user and the TEP marketplace to deploy the application to the ADES and make it available for execution. Initially the application is only available to the user for execution but eventually, the user can submit the application for public deployment at which point other user will be able to discover and executed the application within the TEP environment.
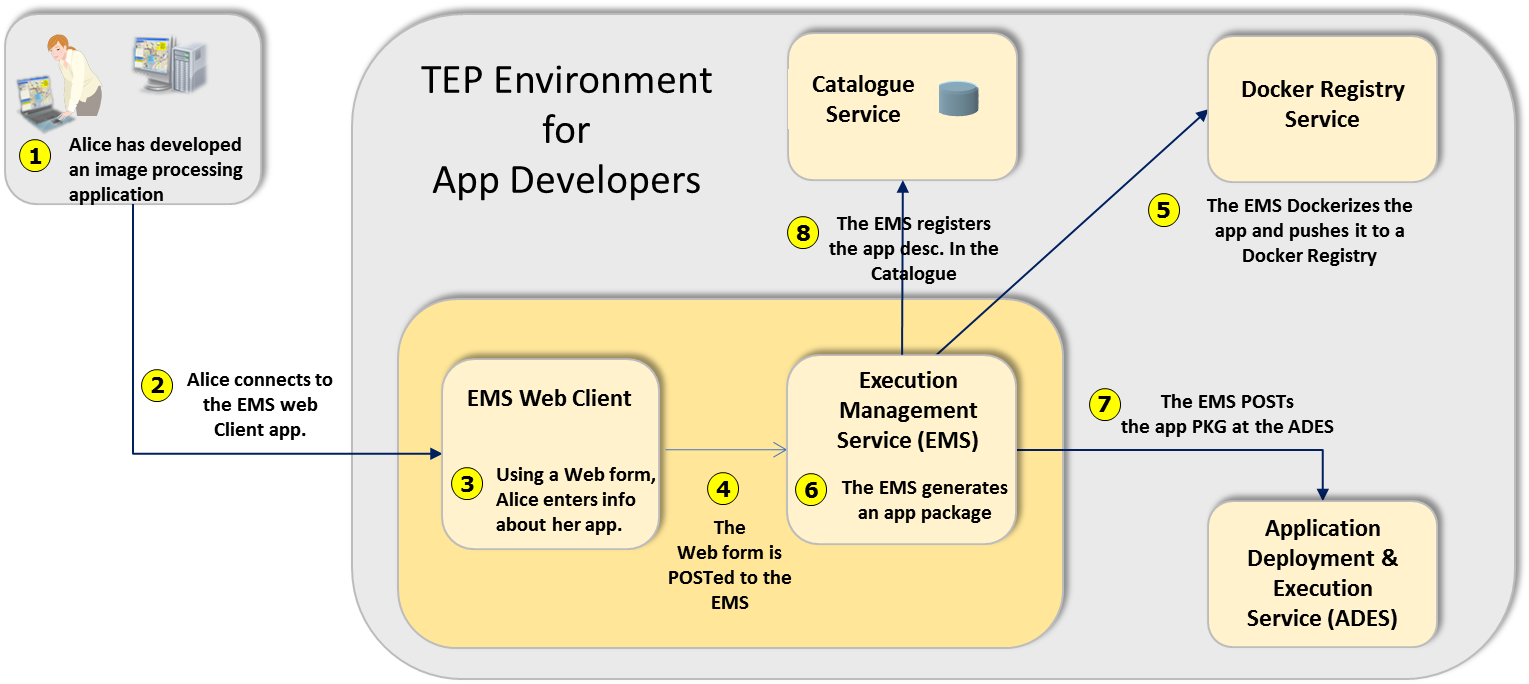 Figure - App Developer Scenario
Figure - App Developer Scenario
5.2. App User Scenario
For a typical TEP user, interaction with the system begins by logging into the TEP marketplace and performing a search for data of interest and/or applications of interest. Since associations are maintained in the catalogue between TEP resources find one (say data) leads to discovering the other (i.e. applications suitable to operate on that data). Having discovered data and application of interest, the user can then proceed to execute the application. This following figure illustrates, at a high level, this workflow.
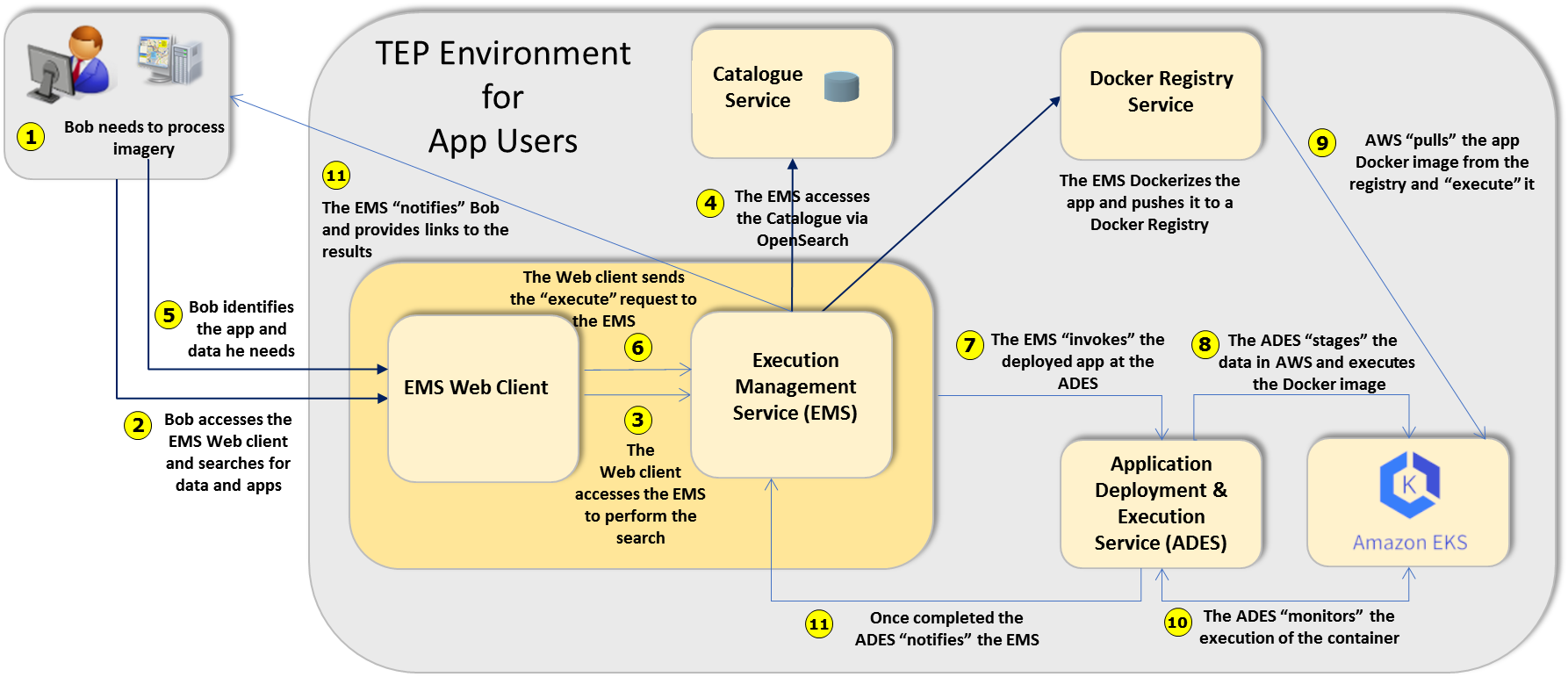 Figure - App User Scenario
Figure - App User Scenario
6. Requirements summary
6.1. Overview
In simple terms, the basic requirement of the TEP marketplace is to enable data processing algorithms uploaded by developers to be run by users, at scale, on very large spatial and non-spatial datasets hosted on the local cloud infrastructure.
-
Developers must be able to package their applications in containers, upload and register them with the system, for discovery by other users.
-
Users must be able to search an online catalogue of available applications and data, and construct job requests that will run their chosen application on the selected subset of data.
-
Results should be delivered either as a downloadable imagery, or via Web services, such as OGC Web Map, Web Map Tile, or Web Coverage services.
All interaction with applications, data and services must be protected by a role-based, spatially-aware authentication and access control system.
6.2. Web front end
The web front-end is the primary entry point for the TEP. The web front-end must satisfy the following requirements:
-
Developer interface
-
Provide web interface to develop, upload and deploy applications.
-
-
User interface
-
Provide web interface to allow TEP exploitation users to:
-
Discover TEP resources (i.e. processes and data)
-
Get quotation for executing process on data
-
Submit execute request to the system
-
Schedule execute request to the system (perhaps periodic)
-
Execute GUI apps (e.g. Jupyter notebooks, QGIS, etc.)
-
AWS Workspaces / AWS AppStream 2.0
-
-
-
6.3. Authentication & Access Control
All aspect of the TEP must be governed by authentication and access control. TEP users must be authenticated in order to access the TEP. Once authenticated, access control must be applied to control what resources the user can access.
The authentication and access control requirements for the TEP include:
-
Single sign-on
-
Role-based access control to TEP resources
-
Spatially aware access control (i.e. restrict or enable access and processing based on spatial constraints)
-
Federated access control allowing access to resources on another federated TEP
6.4. User Workspace Management
Having logged into a TEP, the user is placed in a virtual environment called a "workspace". All the resources of the TEP that the user owns or has access to are available in their workspace. This includes:
-
Apps the user has uploaded or purchased
-
Data the user has uploaded, purchased or has been granted access to
-
Processing results
-
Version control
-
Save and resume
6.5. Job manager
Each processes executed on a TEP will, either explicitly or implicitly, create a job that can be used to:
-
monitor the status of a job (e.g. submitted, running, completed, etc.)
-
access the results of a job
-
cancel a job
-
delete a job (and associated resources)
-
schedule job execution
-
periodic execution or re-execution
-
triggered execution
-
6.6. License manager
It is anticipated that many resources available on a TEP will have associated with then a license. The function of the license manager is to:
-
manage licenses for TEP resource (data, applications, etc.)
-
check license requirement each time a resource is accessed
-
if necessary, solicit license agreements (i.e. click through license) before a resource is accessed
6.7. Notification and analytics
The TEP is a collaborative environment where "events" are constantly occurring. The notification and analytics module allows these events to be logged and that log, in turn, to be used as the basis of a notification system and analytics. The requirements for the notification and analytics module include:
6.7.1. Notifications
-
Notification can be explicitly requested (i.e. via subscription) or they can be implicit (i.e. the system will notify you regardless such as when you exceed a quota or when your processing results are ready)
-
For personal stuff there is a question about whether notifications need to be sent via email or sms, or whether they just you into your notification feed.
-
-
This distinction might be, when its your own stuff in your workspace you automatically get notified; if, however, it is something outside your workspace, it would be op-in and you need to subscribe to get notified.
-
TEP-holdings = data that the TEP offers that is not 'BYOD' data in a user’s workspace
-
Like the GSS, a subscription includes an notification type. Usually that is an email notification but is can also be more general; something like execute this process so this allows processes triggering.
-
For each notification type we need to also define the context-sensitive content of the notification. For example, an SMS notification would be a one-liner while an email notification would include more content and a machine-readable notification would be some kind of JSON document.
-
Potential notification types:
-
email
-
sms
-
webhook
-
process execution
-
feed or notification log
-
-
For the notifications listed bellow we need to fill in:
-
What bits of information are required for each event
-
There will be a set of properties that are common to all events (id, title, timestamp, etc.)
-
There will also be a set of "custom" properties specific to each event type.
-
-
-
Types of notifications
-
User Quota (i.e. the amount of space they can consume in their workspace)
-
when user’s workspace quota is getting close to being exceeded
-
when user’s workspace quota has been exceeded
-
-
ADES events
-
let user know when an application/process is added/modified/deleted on the ADES
-
notify user when processing results are ready
-
notify user when process execution has failed
-
-
TEP-holdings
-
notification when data is added/modified/deleted
-
-
Web services
-
notification when new web service is available
-
notification when new content is added to a web service
-
-
-
Offers a subscription API that supports:
-
Subscribe operation
-
Unsubscribe operation
-
Renew operation (might no be necessary)
-
GetSubscriptions operation
-
Pause subscription operation
-
Resume subscription operation
-
DoNotification operation
-
6.7.2. Analytics
-
Offers and analytics module that can be used (for example) to:
-
Execution analytics
-
What app was executed
-
When the app was executed
-
The specific execute request
-
Who executed it
-
Timing statistics
-
success/failure
-
reference to results
-
Using this set of information all kinds of analytics can be determined
-
-
Create a heatmap of the data usage
-
NOTES: * we envision functions "start_execution", "process_progress" and "finish_execution" to register the fact that a process has started executing, is in the middle of executing and has completed execution * we also envision a function to get this information * all this is probably done within the ADES; the ADES API includes the GetStatus operation that can externalize this information
6.8. Execution and Management service
The execution and management service (EMS) is the primary hub of the TEP marketplace. The EMS interacts with all the other TEP components to enable and coordinate the functionality of the TEP. The functions of the EMS include:
-
Dynamically generate the web front end of the TEP
-
Coordinate app execution with the ADES
-
Act as a coordinate node in federated app execution especially as related to processing workflows
-
Implements the "app store" functionality of the TEP
-
Offer an "app store" API; ideally something similar to the Google or Apple app stores so that developers are presented with a familiar environment for deploying their apps.
-
|
Note
|
Developers should not be able to "deploy" their applications directly to the TEP. Rather, they should "submit" their applications to the TEP and then, after some validation process, the application becomes available for use on the system. |
6.9. Catalogue
The TEP shall include a central catalogue that:
-
Maintains metadata about all TEP resources
-
Maintains associations between TEP resources (e.g. application "A" can operate on data offerings "B" and "C")
-
Offers a search API to make TEP resources discoverable
6.10. Application execution (ADES)
The ADES is responsible for executing user-defined app in the underlying cloud computing environment. As such the ADES must:
-
Deploy user-defined app and make them available through the ADES' API
-
Support workflows and chaining of deployed applications
-
Support delegation (i.e. ability to execute a process on another TEP)
In order to deploy applications, an ADES must accept an "application package" which is a JSON document that:
-
defines the inputs the application accepts
-
defines the output the application generated
-
defines or provides a reference to the execution unit of the application (i.e. the executable code of the application)
The execution unit can be a binary executables bundled in a container (e.g. Docker container) but it can also be code written in some interpreted language such as Python or R.
6.11. Cost estimation and billing (ADES)
User-defined app executed on a TEP run in a cloud computing environment and as such consume chargeable resources. As a result, users will want to be able to get a cost estimate of executing an application on a specified set of inputs. The cost estimation module must:
-
analyze the description of the processes and the inputs specified in a execute request and generate a quotation for this execute request
-
the quotation can include alternative quotations based on different cloud computing resource utilization profiles (e.g. more cloud computing resources leading to shorter execution time and being more expensive versus fewer cloud computing resources leading to longer execution time but being less expensive)
6.12. Parallel execution module (ADES)
The function of the parallel execution module is to analyzes an execute request and the process description of a deployed user-defined app and determine the extent to which the execute request can be parallelized. For example, consider an execute request that references N scenes of satellite imagery as input. If the ADES determines that the N scenes can be processed independently, then the ADES could decide to group the input scenes into M batches and then execute the batches in parallel.
6.13. Results manager (ADES)
The result of executing an app is some output. The function of the result manager is to present the results as requested in the execute request. Results can be:
-
presented in the body of the response
-
stored in persistent storage for repeated retrieval
-
deployed as an OGC API so that the results can be accesses using any OGC API client
Results deployed as an OGC API can be updated and added to via subsequent runs of the process of other data. Subsequent process runs can be ad-hoc but also scheduled and periodic.
6.14. Storage layer
The storage layer is the repository of data in the TEP. The storage layer:
-
stores all "thematic" data offered by the TEP (e.g. image archive of RCM data),
-
stores all user uploaded data,
-
stores all processing results.
Data in the storage layer can be stored to:
-
a database (e.g. RDBMS),
-
file system storage (e.g. for source image for coverages),
-
block or object storage (e.g. S3).
Data in the storage layer can be accessed:
-
directly from the specific storage method
-
via the OGC API for results published as an OGC API deployment
6.15. Federation
Assuming that a trust agreement exists between two TEPs one TEP should be able to call a process on another TEP and retrieve the results of that processing.
7. System Architecture Overview
The main functional components of the TEP marketplace architecture are presented below. Their interactions with each other are detailed in the Scenarios clause.
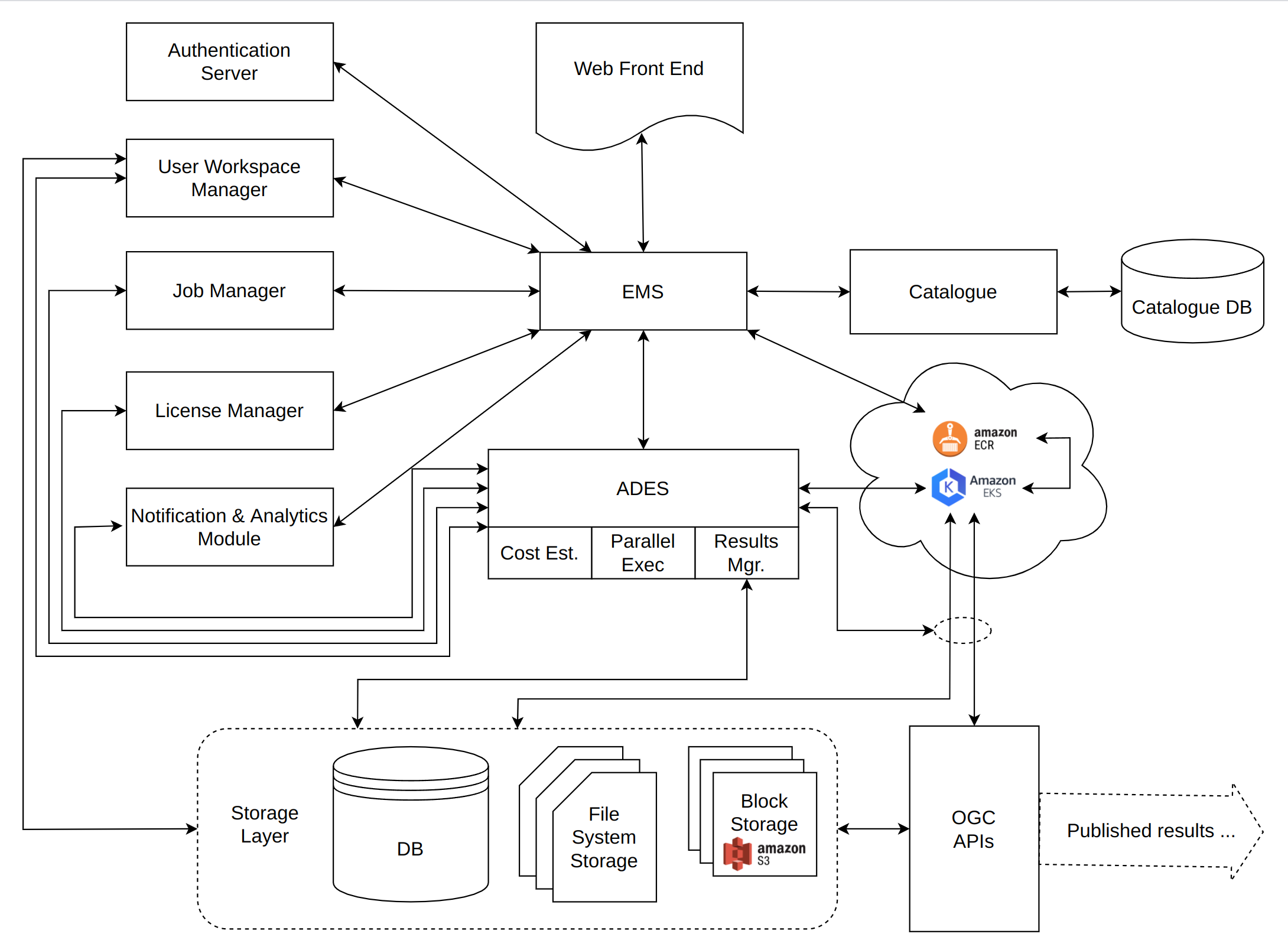 Figure 1 - TEP Architecture
Figure 1 - TEP Architecture
7.1. Web front end
The web from end is the primary entry point for users of the TEP. It is generated by and interacts with the Execution Management Service. It provides interfaces for both app developers and app consumers. It allows developers to upload and register their applications with the system and allows consumers to search for applications and data, execute those applications, access and publish the results.
7.2. Execution Management Service (EMS)
The EMS could fairly be considered the “hub” of the system. It acts as the back end for the Web Client. As such, it manages all interactions between the user and other parts of the system.
It is responsible for:
-
authenticating TEP users
-
enforcing access control rules to TEP resources
-
interfacing with the job manager to monitor job execution and report progress
-
interfacing with the license manager to enforce licensing rules
-
interfacing with the pub/sub manager to receive and trigger notifications
-
creating and managing application packages from uploaded user apps
-
containerizing apps and pushing them to the container registry
-
registering apps with the catalogue and establishing associations between the app and the data it can operate on
-
conducting catalogue searches on behalf of the user, both for apps and data
-
interfacing with the Application Deployment and Execution Service (ADES) to execute apps
7.3. Authentication server
This service provides secure access and rule-based access control to TEP resources. It also provides user management capabilities (i.e. creating users, password recovery, user roles, api keys, etc.)
7.4. User workspace manager
Each TEP user is provided with a workspace. A workspace is a virtual environment that contains all the resources that a TEP user owns or has access to. The workspace manager module implements this virtual environment.
7.5. Job manager
The job manager, manages the lifecycle of jobs created on the TEP. It allows jobs to be monitored, cancelled, deleted, etc. It also allows results to be associated with a job and retrieved once a job is completed.
7.6. License manager
The license manager is responsible for maintaining and enforcing licensing requirements for TEP resources. When necessary, the license manager will (for example) trigger a click-through license to access licensed resources on the TEP.
7.7. The Notification & Analytics module
The Notification & Analytics allow TEP users to subscribe to and receive notifications about various events that can occur in the TEP. For example, the queuing of a job for execution, the completion of the job, exception events, additions of new data to the TEP, etc.
The module also provides analytic tools to view and analyze the event data.
7.8. Application Deployment and Execution Service (ADES)
As its name implies, the ADES is responsible for deploying and executing the app developers’ application packages in the cloud provider’s systems. It interfaces with the cloud provider’s proprietary system for executing Docker containers and manages their execution and monitoring. It is worthy of note that this communication comprises the only cloud-provider-specific interface of the entire architecture. All other components would be identical, regardless which cloud provider is used.
The ADES also interacts with the other modules of the TEP to:
-
store processing results in a user’s workspace
-
this can be storing the results as file, in block storage or even publishing the results as an OGC API
-
-
to communicate the progress of jobs to the job manager
-
to ensure that licensing requirements are satisfied before executing a process
-
to trigger notifications of ADES events
7.9. Catalogue service
The catalogue is a central, searchable repository for both data and applications. It is an OGC-Compliant Service that will serve both app developer and consumer requirements through the EMS.
7.10. Docker registry
Docker is a tool designed to make it easier to create, deploy, and run applications by using containers. Containers allow a developer to package up an application with all of the parts it needs, such as libraries and other dependencies, and ship it all out as one package. By doing so, thanks to the container, the developer can rest assured that the application will run on any other machine regardless of any customized settings that machine might have that could differ from the machine used for writing and testing the code.
A Docker image is a light-weight virtual machine. But unlike a virtual machine, rather than creating a entire virtual operating system, Docker allows applications to use the same kernel as the system that they’re running on and only requires applications be shipped with things not already running on the host computer. This gives a significant performance boost and reduces the size of the application.
Applications in the TEP marketplace will be packaged into Docker containers for execution by the cloud service provider’s system. The Docker registry is a managed repository of Docker containers with API access both for uploading packages (through the EMS) and for accessing and execution them (by the cloud service provider’s execution service).
7.11. Elastic Kubernetes Service (EKS) Container Execution Service
The TEP uses Amazon’s Elastic Kubernetes Service (EKS) to simplify the Docker execution environment and provide scalability for large jobs.
EKS is described by Amazon as “a compute engine that lets you run containers at scale on AWS infrastructure without having to manage clusters or individual virtual servers – This removes the need to choose server types, decide when to scale your clusters, or optimize cluster packing. EKS removes the need for customers to interact with or think about servers or clusters. EKS lets you focus on designing and building your applications instead of managing the infrastructure that runs them.”
Containers running in EKS access TEP data via the storage layer either directly or mediated by the ADES.
7.12. Storage layer
The storage layer is where TEP data is stored. TEP data includes the thematic data that the TEP offers, data uploaded into user workspaces and processing results.
TEP data can be stored in:
-
a MariaDB database,
-
in filesystem storage,
-
or in S3 block or object storage.
Apps deployed on the TEP can access TEP data directly (i.e. the app knows, for example, how to read data from a S3 bucket) or mediated by the ADES (i.e. the ADES stages the data for the application in a form that the application can read).
TEP data case be accesses directly for storage or it can be accesses via an OGC API.
8. Security and Access Control
8.1. Overview
CubeWerx is building some components of the TEP architecture by also extending and enhancing our suite of standards-compliant geospatial web services. Over the past 10 years, we have built out a sophisticated infrastructure for securing such services, based around a cryptographically secure identity token, and “spatially-aware” web services that can use this token to enforce access control.
The Security and access control component is presented in some detail, since 3rd party applications may need to use these authentication methods to access services generated by the TEP.
8.2. Identity Provider Token Service
A sign-in request to the TEP authentication server will return a secure token encoded (in the case of Web applications) in the form of an HTTP cookie called CW_CREDENTIALS. Encoded within the value of this cookie is a small JSON document containing an authenticated set of credentials. These credentials are packaged in an OpenPGP message (RFC 4880) and are signed with the PGP private key of a CubeWerx Authentication Server that is set up to provide authentication for the TEP. All other servers within the TEP are equipped with the public key(s) of the trusted authentication server(s) of that domain. This allows the servers to verify the authenticity of the credentials, since a successful decryption with the public key of one of the trusted authentication servers implies that the credentials must have originated from that authentication server. Note, therefore, that it is not necessary for a server to contact a CubeWerx Authentication Server in order to decrypt or verify the authenticity of a set of credentials.
A user is authenticated by making a login request to a CubeWerx Authentication Server. This can be done directly by having the user visit the CubeWerx Authentication Server with his/her browser, at which point the user will be prompted for a username and password. The authentication server will then pass a CW_CREDENTIALS cookie containing the appropriate credentials back to the browser. Alternatively, a browser-based application can collect the user’s username and password and contact the authentication server on behalf of the user (via either an Ajax request or a redirection to the authentication server with a callback back to the application). Either way, the web browser receives a CW_CREDENTIALS cookie containing the user’s authenticated credentials for that domain.
Since the CwAuth credentials for a particular domain are communicated via an HTTP cookie, web browsers (and thus browser-based applications) will automatically pass along such credentials when communicating with servers within that domain. Furthermore, properly equipped servers can cascade such credentials to other servers further down the service chain by recognizing the CW_CREDENTIALS cookie in the request and passing it along in the HTTP headers of any requests that it makes.
A web service can determine the credentials of the current user in one of two ways:
-
By making a getCredentials request to a CubeWerx Authentication Server and parsing the unencrypted credentials that are returned the response.
-
By decrypting the CW_CREDENTIALS cookie itself with the public key of a known (and trusted) CubeWerx Authentication Server.
A decrypted CW_CREDENTIALS cookie contains an JSON representation of the user’s credentials, and has the following form:
{
"domain": "xyzcorp.com",
"firstName": "John",
"lastName": "Doe",
"eMailAddress": "jdoe@xyzcorp.com",
"username": "jdoe",
"roles": [ "User", "Administrator" ],
"authTime": "2018-04-18T20:19:32.167Z",
"expires": "2018-04-19T08:19:32.167Z",
"loginId": "53vQyeTY",
"hasMaxSeats": true,
"originServer": "https://xyzcorp.com/cubewerx/cwauth"
}All of the properties of this credentials object other than domain and username are optional. If the value of the hasMaxSeats property is false, it’s usually omitted. The originServer property indicates the URL of the CubeWerx Authentication Server that authenticated the credentials.
8.2.1. Authentication Scenarios
There are several situations within the TEP where authentication may be required.
Web-based application authenticating via Ajax request
-
The user clicks a "log in"/"sign in" button on the web-based application.
-
The web-based application prompts the user for a username and password.
-
The web-based application makes an Ajax "login" request to the configured CubeWerx Authentication Server, passing along the user’s username and password.
-
The CubeWerx Authentication Server authenticates the user for the current domain and prepares a set of credentials which it encrypts using a private key and packages into a CW_CREDENTIALS cookie. This CW_CREDENTIALS cookie is then returned to the web-based application via the HTTP response headers. The HTTP response body contains an unencrypted version of the credentials in JSON format.
-
The web browser automatically absorbs the CW_CREDENTIALS cookie and will include it in all future HTTP requests to all servers in the domain that the credentials were authenticated for. The web-based application optionally parses the JSON response and greets the user.
Web-based application redirecting to authentication server
-
The user clicks a "log in"/"sign in" button on the web-based application.
-
The web-based application directs the web browser to the login page of the configured CubeWerx Authentication Server, including a callback URL (back to the appropriate state of the web-based application) as a parameter of the login page’s URL.
-
The CubeWerx Authentication Server prompts the user for a username and password.
-
The CubeWerx Authentication Server authenticates the user for the current domain and prepares a set of credentials which it encrypts using a private key and packages into a CW_CREDENTIALS cookie.
-
The CubeWerx Authentication Server sends a web page back to the user displaying the authenticated credentials. The HTTP response headers of this web page include the CW_CREDENTIALS cookie, which the web browser automatically absorbs.
-
The CubeWerx Authentication Server directs the web browser back to the web-based application, which then greets the user.
Server cascading credentials to another server
-
A server receives a request that includes a CW_CREDENTIALS cookie in its HTTP headers.
-
The server optionally decrypts the CW_CREDENTIALS cookie with the public key of an authentication server. This step is only necessary if this server itself needs to control access based on user identity or if the authenticated user needs to be identified for some other reason (such as for logging or for a personalized greeting message).
-
When making a cascaded request to another server, the server checks the domain of the other server. If it’s in the same second-level domain, it prepares a "Cookie" HTTP header containing a copy of the CW_CREDENTIALS cookie and passes that along with the cascaded request.
Desktop application authenticating via the HTTP Basic Authentication mechanism
-
The desktop application attempts to connect to CubeSERV via an "htcubeserv" URL and is challenged for an HTTP-Basic identity.
-
The user supplies a username and password, and the desktop application attempts the connection to CubeSERV again. (Or the application supplies a configured or cached username and password on the first request.)
-
The CubeSERV authenticates the HTTP-Basic identity and prepares CwAuth credentials for the user by logging into the authentication server on the user’s behalf.
-
The HTTP response includes a CW_CREDENTIALS cookie so that, if the application supports cookies, future requests can be made more efficiently.
8.3. Authentication Server
8.3.1. Overview
The Authentication Server operations can be invoked either via HTTP GET (supplying the parameters as part of the URL) or via HTTP POST (supplying the parameters in the body of the request with an application/x-www-form-urlencoded MIME type). The usage of HTTP POST is recommended for the "login" operation in order to prevent plaintext usernames and passwords from being visible in the URL. Responses that indicate a status in the response body will also report this status via a CwAuth-Status MIME header. If a request to the Authentication Server contains cross-origin resource sharing (CORS) headers, then the origin of the request must be in the same domain as the Authentication Server.
8.3.2. Operations
The Authentication Server supports several operations:
Login
Parameters
operation=login&username=<username>&password=<password>&format=XML|JSON|HTML[&callback=<callbackUrl>]
Usage
Authenticates the user for the current domain (i.e., the second-level domain name of the URL that the CubeWerx Authentication Server was invoked with) and logs him/her in by supplying the user agent (e.g., web browser) with a CW_CREDENTIALS cookie for that domain.
The usage of HTTP POST (supplying the parameters in the body of the request with an application/x-www-form-urlencoded MIME type) is recommended in order to prevent plaintext usernames and passwords from being visible in the URL.
Returns
If authentication is successful, a CW_CREDENTIALS cookie is returned in the response HTTP headers, and a "loginSuccessful" response in the requested format is returned in the response body. The response body includes unencrypted credentials.
<?xml version="1.0" encoding="UTF-8"?>
<CwAuthResponse>
<Status>loginSuccessful</Status>
<CwCredentials>
<Domain>xyzcorp.com</Domain>
<FirstName>John</FirstName>
<LastName>Doe</LastName>
<EMailAddress>jdoe@xyzcorp.com</EMailAddress>
<Username>jdoe</Username>
<Role>User</Role>
<Role>Administrator</Role>
<AuthTime>2018-04-18T20:19:32.167Z</AuthTime>
<Expires>2018-04-19T08:19:32.167Z</Expires>
<LoginId>53vQyeTY</LoginId>
<OriginServer>https://xyzcorp.com/cubewerx/cwauth</OriginServer>
</CwCredentials>
</CwAuthResponse>{
"status": "loginSuccessful",
"credentials": {
"domain": "xyzcorp.com",
"firstName": "John",
"lastName": "Doe",
"eMailAddress": "jdoe@xyzcorp.com",
"username": "jdoe",
"roles": [ "User", "Administrator" ],
"authTime": "2018-04-18T20:19:32.167Z",
"expires": "2018-04-19T08:19:32.167Z",
"loginId": "53vQyeTY",
"originServer": "https://xyzcorp.com/cubewerx/cwauth"
}
}HTML (if a callbackUrl is provided):
(an HTTP redirection to the specified callbackUrl)
HTML (if a callbackUrl is not provided):
(an HTML document showing the user’s new credentials)
If authentication is unsuccessful, a response that indicates a status of "loginFailed" is returned. If unsuccessful login requests are occurring too frequently for this user, the login request is rejected and a response that indicates a status of "loginAttemptsTooFrequent" is returned. This protects the CubeWerx Authentication Server against brute-force password-cracking attempts.
Logout
Usage
Logs the user out of the current domain (i.e., the second-level domain name of the URL that the CubeWerx Authentication Server was invoked with) by requesting that the user agent (e.g., web browser) expire the CW_CREDENTIALS cookie for that domain.
Returns
An empty CW_CREDENTIALS cookie with a cookie expiry time in the past is returned in the response HTTP headers, and a "logoutSuccessful" response in the requested format is returned in the response body.
XML Response:
<?xml version="1.0" encoding="UTF-8"?>
<CwAuthResponse>
<Status>logoutSuccessful</Status>
</CwAuthResponse>JSON Response:
{ "status": "logoutSuccessful" }HTML (if a callbackUrl is provided):
(an HTTP redirection to the specified callbackUrl)
HTML (if a callbackUrl is not provided):
(an HTML document indicating that the user has been logged out)
GetCredentials
Usage
Returns the user’s current credentials (i.e., the unencrypted contents of the user’s CW_CREDENTIALS cookie) for the current domain.
Returns
Either a "credentialsOkay", a "noCredentials", a "credentialsExpired" or a "credentialsInvalid" response in the requested format is returned in the response body. If "credentialsOkay" or "credentialsExpired", the response body includes unencrypted credentials. Note that a CW_CREDENTIALS cookie is not returned in the response HTTP headers, as this would be redundant. The "credentialsInvalid" response response is returned in situations where the user has credentials but they are not recognized by this authentication server.
XML Responses:
<?xml version="1.0" encoding="UTF-8"?>
<CwAuthResponse>
<Status>credentialsOkay</Status>
<CwCredentials>
<Domain>xyzcorp.com</Domain>
<FirstName>John</FirstName>
<LastName>Doe</LastName>
<EMailAddress>jdoe@xyzcorp.com</EMailAddress>
<Username>jdoe</Username>
<Role>User</Role>
<Role>Administrator</Role>
<AuthTime>2018-04-18T20:19:32.167Z</AuthTime>
<Expires>2018-04-19T08:19:32.167Z</Expires>
<LoginId>53vQyeTY</LoginId>
<OriginServer>https://xyzcorp.com/cubewerx/cwauth</OriginServer>
</CwCredentials>
</CwAuthResponse>or
<?xml version="1.0" encoding="UTF-8"?>
<CwAuthResponse>
<Status>noCredentials</Status>
</CwAuthResponse>or
<?xml version="1.0" encoding="UTF-8"?>
<CwAuthResponse>
<Status>credentialsExpired</Status>
<CwCredentials>
...
</CwCredentials>
</CwAuthResponse>or
<?xml version="1.0" encoding="UTF-8"?>
<CwAuthResponse>
<Status>credentialsInvalid</Status>
</CwAuthResponse>*JSON Responses: *
{
"status": "credentialsOkay",
"credentials": {
"domain": "xyzcorp.com",
"firstName": "John",
"lastName": "Doe",
"eMailAddress": "jdoe@xyzcorp.com",
"username": "jdoe",
"roles": [ "User", "Administrator" ],
"authTime": "2018-04-18T20:19:32.167Z",
"expires": "2018-04-19T08:19:32.167Z",
"loginId": "53vQyeTY",
"originServer": "https://xyzcorp.com/cubewerx/cwauth"
}
}or
{ "status": "noCredentials" }or
{
"status": "credentialsExpired",
"credentials": {
...
}
}or
{ "status": "credentialsInvalid" }HTML Response:
(an HTML document showing the user’s current credentials)
(if a callbackUrl is provided, then the HTML response document will include a button which allows the user to go to that URL, returning the user to the web application that invoked the getCredentials operation)
8.4. Access Control for TEP Components and Web Services
The access control mechanism to be deployed for the TEP and employed by the CubeSERV OGC Web Services is an internal software module built into all CubeWerx Web services that controls access to services, data and map layers in a number of ways, based on the identity of the user. It is configured as a set of rules (expressed as XML), where each rule has an appliesTo attribute indicating which user(s) or roles the rule applies to. An individual user may trigger more than one applicable rule, or none. If more than one rule is applicable, then the user is granted access to the union of what the applicable rules grant. Rules can be configured to expire after a certain time, allowing subscription times to be configured.
8.4.1. Identity Types
The following identity types can be specified:
-
IP address (or address range)
-
HTTP Basic identity
-
CubeWerx Identity Token (user, role or any)
-
OAuth Identity Token
-
OpenID Token
-
Everybody
8.4.2. Spatially Aware Access Control
Access control is implemented at the Web Service level in all TEP components, which enables each component to make intelligent decisions based on its individual domain “knowledge”.
For instance, based on a user’s identity, a map service can be instructed to allow access to certain map layers, or certain operations of the service, as well as restricting the request to certain geographical regions, represented by complex polygons if necessary, or limiting requests for high resolution data to lower resolution representations of that data. Images can be watermarked for certain roles or users if required.
This component is embedded in the Web Processing Servers that make up the TEP components, allow TEP administrators to set permissions and grant or deny access to various aspects of the system.
9. Workspace manager
Associated with each TEP user is a workspace. A workspace is a virtual environment where a user, depending on their role, can maintain and organize all their TEP resources. TEP resources include licenses, data, applications, jobs, etc. The workspace environment can also provide resource such as IDEs (e.g. Jupyter notebooks) for developing applications, etc.
The following sections describe the individual sub-components of the workspace manager.
9.1. TEP workspace
A TEP Marketplace user must have the ability to upload their own data. This area will be called "the user’s TEP workspace". To support this, the TEP Marketplace will have an S3 bucket, accessible only by the TEP Marketplace server, with the following directory structure:
users/
<username1>/
workspace/
...
jobs/
<username2>/
workspace/
...
jobs/
<username3>/
workspace/
...
jobs/
[...]Under a user’s workspace/ directory is a free-form directory structure of files that’s under the user’s complete control. It consists of:
-
all of the source data that the user uploads (e.g., GeoTIFF files, GeoJSON files, etc.), organized into whatever directory structure makes sense to the user
-
anything else that the TEP Marketplace apps need to operate
-
processing results (i.e., output of WPS), under a hardcoded
jobs/directory
The user should be presented with this directory as a complete filesystem through the TEP Marketplace, manipulatable in the standard filesystem ways. The only way the user can access this directory structure is through the TEP Marketplace (authenticated via CwAuth). There will be no direct access.
The reason for the extra workspace/ directory level is to allow the possibility of other TEP-managed directories to exist in S3 per username.
The user should be able to select one or more files or directories in their workspace and do things like download or delete the files. If the files and/or directories are data files, the user should also be given the option to expose them as a web service (see the Exposing workspace data as web services section). The user should also be able up upload new files and directories.
There will be per-user quotas on the size of a user’s workspace. The user should be given a visual indication of how full their workspace is (e.g., with a progress bar and/or "xGB of xGB used (x%)". We can determine the number of bytes taken up by an S3 directory with the command:
s3 size -recursive s3://{bucket}/{path}/9.2. Workflow management
The TEP workspace will use a MariaDB database (on the same database system where cw_auth exists) called cw_tep, which has the following table:
CREATE TABLE workflows (
username VARCHAR(255) NOT NULL,
title VARCHAR(255),
script LONGTEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT '1970-01-02',
updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (username) REFERENCES cw_auth.users (username)
ON DELETE CASCADE ON UPDATE CASCADE
) CHARACTER SET utf8 COLLATE utf8_bin;This table can be JOINed with the cw_auth.users table to determine the user’s full name and e-mail address, etc.
The TEP Marketplace GUI will have some sort of workflow editor, and will store the workflows in this table. The script will likely be CQL, so the GUI will need to know how to parse and generate CQL.
9.3. App management
App management within the TEP Marketplace is described in the License manager section of this document.
9.4. List of owned jobs
The user should be presented with a list of their current jobs (in whatever state they’re in - in progress, completed, etc.). This information can be provided to the TEP Marketplace GUI by the ADES and/or the jobs table (see section ???). If possible, a progress bar (with an estimated time to completion) should be presented for in-progress jobs.
9.5. Job results
Upon completion of a process, the results (and logs, etc.) will automatically be stored (by the WPS itself) in the user’s workspace under a jobs/{jobId}/ directory.
9.6. Exposing workspace data as web services
A user should be able to select any data file (e.g., a GeoTIFF or GeoJSON file) or directory (e.g., jobs/{jobId}/Output) in their workspace and expose it as a CubeSERV web service (which provides several OGC web service endpoints). The user should be given the option to "expose as new web service" or "add to existing web service". Perhaps there can also be a shortcut way of doing this upon completion of a job.
The TEP will expose a single CubeWerx Suite web deployment and use only the default instance. To expose a set of one or more data files through CubeSERV, it must be first loaded as a CubeSTOR MariaDB feature set. Each TEP user will be assigned exactly one CubeSTOR data store, whose name is the user’s username. When a TEP user is created, the following steps must be taken to support this:
-
Create a CubeSTOR MariaDB data store whose name is the user’s username.
-
Add the following entry to the namedDataStores.xml file:
<DataStore name="{username}">
<Type>mariadb</Type>
<Source>{username}</Source>
</DataStore>-
Add the following entry to the accessControlRules.xml file:
<Rule appliesTo="cwAuth{{username}}">
<Allow>
<Operation class="*"/>
<Content dataStore="{username}" name="*"/>
</Allow>
</Rule>Conversely, these things must be removed when the TEP user is deleted.
The steps to expose a set of one or more data files as a new web service are:
-
Create a new CubeSTOR MariaDB feature set in that user’s data store. The feature-set name should be the job ID, data filename, or data directory name, and the user should be prompted for a title.
-
Set up some sort of good default style for map rendering. (In a future version, the user could even be prompted for options here.)
-
Register the specified source file(s) as data sources of this feature set.
To add one or more data files to an existing web service, it’s simply a matter of registering the specified source file(s) as new data sources.
The TEP GUI will need to present the user with the list of their currently-exposed web services. This list can be derived simply by querying the user’s CubeSTOR data store for the list of feature sets that are loaded into it. From this list, the user should be able to:
-
Make the web service either public or private by adding or removing the following feature-set specific entry to/from
accessControlRules.xml:
<Rule appliesTo="everybody">
<Allow>
<Operation class="GetMap"/>
<Operation class="GetFeature"/>
<Operation class="GetFeatureInfo"/>
<Content dataStore="{username}" name="{featureSetName}"/>
</Allow>
</Rule>-
Remove the web service (by removing the feature set and removing the feature-set specific entries in accessControlRules.xml.
-
In the future, possibly re-title the web service (by retitling the underlying feature set), etc.
With this arrangement, the following web-service URLs will exist:
- A WMS serving {username}'s exposed feature sets
-
https://{wherever}/cubeserv?DATASTORE={username}&SERVICE=WMS
- A WMS serving all exposed feature sets of all TEP users
- A WMTS serving {username}'s exposed feature sets
-
https://{wherever}/cubeserv?DATASTORE={username}&SERVICE=WMTS
- A WMTS serving all exposed feature sets of all TEP users
- A WFS serving {username}'s exposed feature sets
-
https://{wherever}/cubeserv?DATASTORE={username}&SERVICE=WFS
- A WCS serving {username}'s exposed feature sets
-
https://{wherever}/cubeserv?DATASTORE={username}&SERVICE=WCS
- An OGC API landing page for {username}'s exposed feature sets
- An OGC API endpoint for one of {username}'s exposed feature sets
-
https://{wherever}/cubeserv/default/ogcApi/{username}/collections/{collectionId}
All of these URLs, except for the last one, will always exist for all TEP users. The last one is feature-set specific, so there will be zero or more of them per user.
9.7. Sharing
In the first version of the TEP Marketplace, it has been tentatively agreed that the only way to share data with others will be by exposing it as a web service, marking it as "public", and sharing the URL(s) to this web service.
In a future version, we can allow a TEP user to share arbitrary content in their workspace with other users. To accommodate this, we can add the following table to the cw_tep database:
CREATE TABLE access_control (
username VARCHAR(255) NOT NULL,
path VARCHAR(4096) NOT NULL,
grant_user VARCHAR(255),
grant_type VARCHAR(255) NOT NULL,
FOREIGN KEY (username) REFERENCES cw_auth.users (username)
ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY (grant_user) REFERENCES cw_auth.users (username)
ON DELETE CASCADE ON UPDATE CASCADE
) CHARACTER SET utf8 COLLATE utf8_bin;username is the username of the TEP user granting access to something in their workspace. path is the path of the file or directory being shared, and is relative to the root of the user’s workspace. grant_user is the username of the TEP user who’s being granted access, or NULL to grant all users access. grant_type is the type of access granted. In the first implementation of this mechanism, this will probably be limited to "r" for read-only access.
This table can be JOINed with the cw_auth.users table to determine the user’s full name and e-mail address, etc.
A user should be able to grant or revoke access to arbitrary files and directories in their workspace by selecting the appropriate option in the file-or-directory-specific menu in their workspace view.
Each user’s workspace view will have a directory called shared/ (that is not renameable or removable) whose subdirectories are the usernames of users who have granted the user access to at least one thing. Under these subdirectories will be the files and directories of the things being shared. In this way the user can access (and refer to in process inputs) other user’s shared files in exactly the same way as they refer to their own. This shared/ directory wouldn’t actually exist in S3; it would be a virtual directory that is grafted on by the GUI.
10. Catalogue service
10.1. Overview
Many of the components of the TEP marketplace are driven by the catalogue. The function of the catalogue is to:
-
keep track of the public and private resources offered by the TEP marketplace
-
keep track of associations between those resources
-
allow searching the catalogue to discover TEP resources
-
bind to the discovered resources
The catalogue for the TEP marketplace is based on the OGC API - Records standard.
10.2. Record
The atomic unit of information in the catalogue is the record. The following table lists the properties of a record:
| Queryables | Description |
|---|---|
recordId |
A unique record identifier assigned by the server. |
recordCreated |
The date this record was created in the server. |
recordUpdated |
The most recent date on which the record was changed. |
links |
A list of links for navigating the API, links for accessing the resource described by this records and links to other resources associated with the resource described by this record, etc. |
type |
The nature or genre of the resource. |
title |
A human-readable name given to the resource. |
description |
A free-text description of the resource. |
keywords |
A list of keywords or tag associated with the resource. |
keywordsCodespace |
A reference to a controlled vocabulary used for the keywords property. |
language |
This refers to the natural language used for textual values. |
externalId |
An identifier for the resource assigned by an external entity. |
created |
The date the resource was created. |
updated |
The more recent date on which the resource was changed. |
publisher |
The entity making the resource available. |
themes |
A knowledge organization system used to classify the resource. |
formats |
A list of available distributions for the resource. |
contactPoint |
An entity to contact about the resource. |
license |
A legal document under which the resource is made available. |
rights |
A statement that concerns all rights not addressed by the license such as a copyright statement. |
extent |
The spatio-temporal coverage of the resource. |
associations |
The OGC API Records specification defines a GeoJSON encoding for a record. The following is an example of the GeoJSON-encoded catalogue record describing a process that computes NDVI and operates on RCM2 and Sentinel2 data:
{
"id": "urn:uuid:66f5318a-b1b6-11ec-bed4-bb5d1e67b39f",
"type": "Feature",
"geometry": null,
"properties": {
"recordCreated": "2022-03-01",
"recordUpdated": "2022-03-25",
"type": "process",
"title": "Calculation of NDVI using the SNAP toolbox for Sentinel-2",
"description": "Calculation of NDVI using the SNAP toolbox for Sentinel-2",
"keywords": [ "NDVI", "SNAP", "process" ],
"language": "en",
"externalId": [
{"value": "http://www.cubewerx.com/cubewerx/cubeserv/tep/processes/NDVICalculation"}
],
"created": "2022-01-18",
"updated": "2222-01-18",
"publisher": "https://www.cubewerx.com",
"formats": [ "image/geo+tiff" ],
"contactPoint": "https://woudc.org/contact.php",
"license": "https://woudc.org/about/data-policy.php",
},
"links": [
{
"rel": "describedBy",
"type": "application/json",
"title": "OGC API Processes Description of the NDVICalculation Process",
"http://www.cubewerx.com/cubewerx/cubeserv/tep/processes/NDVICalculation?f=json"
},
{
"rel": "operatesOn",
"type": "application/json",
"title": "OGC API Coverages Description of the RCM2 Data Collection",
"http://www.cubewerx.com/cubewerx/cubeserv/tep/collections/rcm2?f=json"
},
{
"rel": "operatesOn",
"type": "application/json",
"title": "OGC API Coverages Description of the Sentinel2 Data Collection",
"http://www.cubewerx.com/cubewerx/cubeserv/tep/collections/sentinel2?f=json"
},
{
"rel": "alternate",
"type": "text/html",
"title": "This document as HTML",
"href": "https://www.cubewerx.com/cubewerx/cubeserv/tep/tepcat/item/urn:uuid:66f5318a-b1b6-11ec-bed4-bb5d1e67b39f"
}
]
}10.3. Resource types
The following list of resource types that are expected to be catalgued in the TEP:
-
collections
-
collections of features (vector or rasters)
-
sources (e.g. image sources for coverages)
-
-
collections of data products (e.g. RCM, Sentinel-1, etc.)
-
-
application or processes deployed on the TEP
-
feature access endpoint
-
coverage access endpoints
-
map access endpoints
-
tile access endpoints
-
style documents
10.4. Association types
Associations are expressed in the form <source resource> <association> <target resource>. The following list of associations and expected to exist among catalogues resources:
-
Renders
-
The source of the association RENDERS the target of the association.
-
e.g. Map access endpoint X RENDERS feature collection Y.
-
-
Tiles
-
The source to the association TILES the target of the association.
-
e.g. Tile access endpoint X TILES feature collection Y.
-
-
ParentOf
-
The source the association is the PARENTOF the target of the association.
-
e.g. Feature collection X is the PARENTOF feature Y.
-
-
Styles
-
The source of the association STYLES the target of the association.
-
e.g. Style document X STYLES feature collection Y.
-
-
OperatesOn
-
The source of the association OPERATESON the target of the association.
-
e.g. Application X OPERATESON data product Y.
-
-
Offers
-
The source of association OFFERS the target of the association.
-
e.g. Features access endpoint X OFFERS feature collection Y.
-
-
Describes
-
The source of the association DESCRIBES the target of the association.
-
OpenAPI document X DESCRIBES coverage accesspoint Y.
-
-
Asset
-
The source of the association is an ASSET of the target of the associations.
-
e.g. Thumbnail X is an ASSET of data product Y (i.e. downloadable or streambale data associated with the data product).
-
10.5. Search API
The Records API allows a subset of records to be retrieved from a catalogue using a logically connected set of predicates that may include spatial and/or temporal predicates.
The Records API extends OGC API - Features - Core: Part 1 to provide modern API patterns and encodings to facilitate to facilitate flexible discovery of resource available on the TEP.
The OGC API Features API that has been:
-
extended with additional parameters at the
/collections/{collectionId}/itemsendpoint, -
and constrained to a single information model (i.e. the record).
The following tables summarizes the access paths and relation types of the TEP catalogue search API:
| Path Template | Relation | Resource |
|---|---|---|
Common |
||
none |
Landing page of the catalogue |
|
|
API Description (optional) of the catalogue |
|
|
OGC conformance classes implemented for the catalogue server |
|
|
Metadata about the catalogues available in the TEP. |
|
Metadata describing a specific catalogue with unique identifier |
||
Records |
||
|
The search endpoint for the catalogue with identifier |
|
|
The URL of a specific record in the catalogue with record identifier |
|
Where:
-
{collectionId} = an identifier for the catalogue
-
{recordId} = an identifier for a specific record within a catalogue
|
Note
|
At the moment it is anticipated that the TEP will only have a single catalogue storing all the metadata of the system. However, the API is flexible enough to accommodate multiple catalogues if that becomes a requirement. |
The following tables lists the query parameter that may be used at the search endpoint to query the TEP catalogue:
| Parameter name | Description |
|---|---|
bbox |
A bounding box. If the spatial extent of the record intersects the specified bounding box then the record shall be presented in the response document. |
datetime |
A time instance or time period. If the temporal extent of the record intersects the specified data/time value then the record shall be presented in the response document. |
limit |
The number of records to be presented in a response document. |
q |
A comma-separated list of search terms. If any server-chosen text field in the record contains 1 or more of the terms listed then this records shall appear in the response set. |
type |
An equality predicate consistent of a comma-separated list of resource types. Only records of the listed type shall appear in the resource set. |
externalid |
An equality predicate consistent of a comma-separated list of external resource identifiers. Only records with the specified external identifiers shall appear in the response set. |
prop=value |
Equality predicates with any queryable (see: /collections/{catalogueId}/queryables) |
filter |
A CQL2 filter expression; CQL2 is similar to a SQL where clause |
filter-lang |
Fixed to the value |
filter-crs |
The coordinate reference system for any geometric values used in a |
GET /collections/tep-catalogue/items?bbox=-79.610988,43.555105,-79.156274,43.871673&type=rcm210.6. Loading the catalogue
By default the catalogue will access the internal CubeWerx Suite data dictionary to make all the metadata about available features sets, sources, data products, etc. accessible through the catalogue’s API. Thus, whenever a new resource is added to the TEP through CubeWerx Suite, it will automatically become discoverable via the catalogue’s API.
S3 triggers will be used to keep the catalogue’s information about the TEP holdings and user’s TEP workspace data up to date. Whenever data is added to the TEP holdings or the user’s TEP workspace, an S3 trigger will invoke a Lambda function that will generate a new catalogue record describing the newly added data and then HTTP POST that record to the TEP’s catalogue server. If data is removed from the TEP holdings or the user’s TEP workspace, an S3 trigger will invoke a Lambda function that will remove the corresponding record from the catalogue.
The catalogue also supports a Harvest API and a "CRUD" API so that other metadata can be explicitly loaded into the catalogue if necessary. Using the Harvest API, a reference to a knows resource type can be provided to the catalogue which will then read the metadata about the resource and populate the catalogue. Similarly a catalogue records can be externally prepared to describe a resource and pushed to the catalogue using the standard "CRUD" methods.
11. Jobs manager
11.1. Overview
Whenever a process is executed, whether synchronously or asynchronously, a job resource is implicitly created. These job resources are managed through the jobs API describe is this clause.
11.2. Getting a list of jobs
The TEP Marketplace API supports the HTTP GET operation at the /jobs endpoint. The body of the GET response contains a list of jobs. The following schema fragment defines the schema of the response:
type: object
required:
- jobs
- links
properties:
jobs:
type: array
items:
$ref: "code/openapi/schemas/statusInfo.yaml"
links:
type: array
items:
$ref: "code/openapi/schemas/link.yaml"By default all jobs on the system are returned. However, the following tables defined a set of query parameters that can be used to filter the subset of jobs that are listed in the response.
| Parameter name | Type | Default value | type |
|---|---|---|---|
array of string |
process |
processID |
array of string |
none defined |
status |
array of string |
none defined |
datetime |
string (date-time) |
none defined |
limit |
The type parameter allows filtering of the results based on the type of service that created the job. For the TEP marketplace the value process is the default value indicated that only jobs created as a result of executing an app will be listed.
The processID parameter allows filtering of the results based on a list of one or more app identifiers (i.e. property processID).
The status parameter allows filtering of the results based on the specified list of job statuses. Valid status values include accepted, running, successful, failed and dismissed.
The datetime parameter allows filtering of the results based on when a job was created. The datetime parameter is an ISO 8601 interval defined by the following BNF:
interval-closed = date-time "/" date-time
interval-open-start = [".."] "/" date-time
interval-open-end = date-time "/" [".."]
interval = interval-closed | interval-open-start | interval-open-end
datetime = date-time | intervalIf the value of the datetime parameter is a specific time instance than only jobs created at time time instance are listed in the response. If the value of the datetime parameter is an interval then only jobs created during the specific interval are listed in the response.
The limit parameter defines the number of jobs that are presented is a single response. If there are more jobs than the value of the limit parameter, links (rel="next" or rel="prev") are included in the response to navigate to subsequent or previous response pages.
11.3. Getting the status of a job
The TEP Marketplace API supports the HTTP GET operation at the /jobs/{jobsID} endpoint. The body of the GET response contains a status of the specified job identified by its jobID. The following schema fragment defines the schema of the response:
type: object
required:
- jobID
- status
- type
properties:
processID:
type: string
type:
type: string
enum:
- process
jobID:
type: string
status:
$ref: "statusCode.yaml"
message:
type: string
created:
type: string
format: date-time
started:
type: string
format: date-time
finished:
type: string
format: date-time
updated:
type: string
format: date-time
progress:
type: integer
minimum: 0
maximum: 100
links:
type: array
items:
$ref: "link.yaml"The following schema defines the possible statuses that a job can assume:
type: string
nullable: false
enum:
- accepted
- running
- successful
- failed
- dismissedAs indicated above, the status response includes a links section. This section can contain links to an endpoint for ongoing monitoring of the job (i.e. rel="monitor") or an endpoint to cancel a running job (i.e. rel="cancel") or a link to delete the job (i.e. rel="edit") and thus free any storage resources that the job might be consuming.
11.4. Getting a run log for a job
The TEP Marketplace API supports the HTTP GET operation at the /jobs/{jobID}/runlog endpoint. The body of the GET response contains a runlog for that job that is current as of the moment the GET operation was executed. The response of the operation is a text/plain document that contains a run log of the job.
11.5. Getting the results of a job
11.5.1. Getting all the results at once
The TEP Marketplace API supports the HTTP GET operation at the /jobs/{jobID}/results endpoint.
If the job status is failed then the following schema fragment defines the schema of the response:
title: Exception Schema
description: JSON schema for exceptions based on RFC 7807
type: object
required:
- type
properties:
type:
type: string
title:
type: string
status:
type: integer
detail:
type: string
instance:
type: string
additionalProperties: trueIf the job status is successful the response contains all the results of processing (either in-line or by reference) and is defined by the following schema fragments:
additionalProperties:
$ref: "inlineOrRefData.yaml"oneOf:
- $ref: "inputValueNoObject.yaml"
- $ref: "qualifiedInputValue.yaml"
- $ref: "link.yaml"oneOf:
- type: string
- type: number
- type: integer
- type: boolean
- type: array
- $ref: "binaryInputValue.yaml"
- $ref: "bbox.yaml"type: string
format: bytetype: object
required:
- bbox
properties:
bbox:
type: array
oneOf:
- minItems: 4
maxItems: 4
- minItems: 6
maxItems: 6
items:
type: number
crs:
type: string
format: uri
default: "http://www.opengis.net/def/crs/OGC/1.3/CRS84"
enum:
- "http://www.opengis.net/def/crs/OGC/1.3/CRS84"
- "http://www.opengis.net/def/crs/OGC/0/CRS84h"allOf:
- $ref: "format.yaml"
- type: object
required:
- value
properties:
value:
$ref: "inputValue.yaml"type: object
properties:
mediaType:
type: string
encoding:
type: string
schema:
oneOf:
- type: string
format: url
- type: objectoneOf:
- $ref: "inputValueNoObject.yaml"
- type: objecttype: object
required:
- href
properties:
href:
type: string
rel:
type: string
example: service
type:
type: string
example: application/json
hreflang:
type: string
example: en
title:
type: string===
11.5.2. Getting results individually
The TEP Marketplace API supports the HTTP GET operation at the /jobs/{jobID}/results/{outputID} endpoint. The value of the outputID parameter is an output identifier as defined in the process description. This endpoint allows the
outputs of processing to be retrieved individually.
The content of the response depends on the definition of the output. For example, if the requested output is a GeoTIFF image than the response body will contain the image and the content type of the response will be set of image/geo+tiff.
11.6. Cancelling or removing a job
The TEP Marketplace API supports the HTTP DELETE operation at the /jobs/{jobsID} endpoint. The result of this operation depends on the status of the job. If the job status is currently accepted or running then the operation will cancel the job and set the job’s status to dismissed. If the job status is successful, failed or dismissed then the operation will remove the job and delete any artifacts associated with the job.
12. License manager
It is highly likely that licenses will be associated with most resources offered by the TEP. The license manager is responsible to enforcing these licenses. This means checking for licensing requirements before a resource is accessed. As a result of the check access to a resource could be granted or denied. The use of a data set or application (process) may require the acceptance of one or both of the following types of licenses:
-
one or more click-through term-of-use licenses
-
a purchase license
The license requirements of a data set are advertised reported by the catalog. The license requirements of an application (process) are advertised reported by the ADES (via a license key).
The TEP Marketplace should keep track of the licenses that each user has obtained for each data set and application. It should also keep track of the last time each data set and application has been used by a user so that a user can be presented with a "most recently used" list for each of these two resource types. This can be done by introducing the following table in the cw_tep database:
CREATE TABLE resources (
username VARCHAR(255) NOT NULL,
resource_type VARCHAR(16) NOT NULL, # for now, one of "app" or "data"
resource_url VARCHAR(255) NOT NULL,
last_used TIMESTAMP,
agreed_to BOOLEAN NOT NULL,
bill_id VARCHAR(255),
FOREIGN KEY (username) REFERENCES cw_auth.users (username)
ON DELETE CASCADE ON UPDATE CASCADE
) CHARACTER SET utf8 COLLATE utf8_bin;If a data set or application has more than one click-through term-of-use license, the agreed_to boolean should only be set after the user agrees to all of them.
Every time a user invokes a data set or application, the TEP Marketplace should:
-
Update the last_used field of the appropriate record in the
resourcestable, or add the record if it doesn’t exist. -
Consult the catalog or the ADES to determine license requirements.
-
If the data set or application has any click-through licenses and
agreed_tois false, prompt the user to agree to these licenses. Disallow access until the user agrees. When the user agrees, setagreed_toto true. -
If the data set or application has a purchase license and
bill_idis NULL, prompt the user to pay the appropriate amount. Disallow access until payment is complete. When payment is complete, record the bill ID inbill_id.
For convenience, the TEP Marketplace should provide the user with a list of their most-recently-used data sets and apps, driven by the last_used field in the resources table.
It has been tentatively agreed that the first version of the TEP Marketplace will not have a purchase mechanism. However, data sets and applications may still advertise a cost as proof of concept.
13. Notification module
A TEP Marketplace user should be able to subscribe to receive notifications about certain types of TEP events. The TEP Marketplace should provide a user with a list of their current subscriptions and allow the user to add and remove subscriptions (and perhaps put subscriptions on hold, etc.). A subscription can have filters (specific to the type of event) which narrow down which events the user is interested in. Each subscription can have one or more notification methods, including e-mail, SMS, etc. In addition, the TEP Marketplace will provide a news feed to the user, providing a single-line notification of each subscribed-to TEP event that occurs.
13.1. Event types
There will be many different types of events. Each event type will have:
-
an event-type ID
-
a set of zero or more subscription filters (queryables)
-
a set of zero or more event properties, i.e., the bits of data that must be provided for an event of this type
-
a title template, i.e., the single line of English text that will be used to present the notification to the user (e.g., news feed line, SMS message or e-mail subject line), with template variables representing event property values
-
a body template, i.e., possibly multiple lines of English text, possibly HTML-formatted, that will be used to present the event details to the user (e.g., news feed popup or e-mail body), with template variables representing event property values
The following is a tentative list of the types of events that the TEP marketplace should be able to handle:
13.1.1. The user has reached 75% of their workspace size quota
- event-type ID
-
quotaWarning1
- subscription filters
-
username (automatically applied; i.e., not a GUI option)
- event properties
-
username
currentNumOfMBytes
quotaNumOfMBytes - title template
-
You have reached 75% of your quota of {quotaNumOfMBytes}MB.
- body template
-
The size of your TEP Workspace has reached 75% of your quota of {quotaNumOfMBytes}MB. To increase your quota, [TBD…]
13.1.2. The user has reached 90% of their workspace size quota
- event-type ID
-
quotaWarning2
- subscription filters
-
username (automatically applied; i.e., not a GUI option)
- event properties
-
username
currentNumOfMBytes
quotaNumOfMBytes - title template
-
You have reached 90% of your quota of {quotaNumOfMBytes}MB.
- body template
-
The size of your TEP Workspace has reached 90% of your quota of {quotaNumOfMBytes}MB. To increase your quota, [TBD…]
13.1.3. The user has exceeded their workspace size quota
- event-type ID
-
quotaExceeded
- subscription filters
-
username (automatically applied; i.e., not a GUI option)
- event properties
-
username
currentNumOfMBytes
quotaNumOfMBytes - title template
-
You have exceeded your quota of {quotaNumOfMBytes}MB.
- body template
-
The size of your TEP Workspace has exceeded your quota of {quotaNumOfMBytes}MB. To increase your quota, [TBD…]
13.1.4. A job has completed and processing results are ready
- event-type ID
-
jobCompleted
- subscription filters
-
username (automatically applied; i.e., not a GUI option)
jobId - event properties
-
username
jobId
startedOn
jobUrl (URL to the job details in the TEP Marketplace) - title template
-
Job {jobId} has completed and its results are ready.
- body template
-
Job {jobId} (started on {startedOn}) has completed execution, and its results are <a href="jobUrl">ready</a>.
13.1.5. A job (i.e., process execution) has failed
- event-type ID
-
jobFailed
- subscription filters
-
username (automatically applied; i.e., not a GUI option)
jobId - event properties
-
username
jobId
startedOn
jobUrl (URL to the job details in the TEP Marketplace) - title template
-
Job {jobId} has failed.
- body template
-
Job {jobId} (started on {startedOn}) has failed execution. Details are available <a href="jobUrl">here</a>.
13.1.6. An application/process has been added to the TEP Marketplace
- event-type ID
-
appAdded
- subscription filters
-
dataTypes (?)
- event properties
-
appUrl
appTitle
appDescription
dataTypes(?)
??? - title template
-
A new application called "{appTitle}" is available.
- body template
-
A new application called "{appTitle}" is <a href={appUrl}>available<a>. Its description is as follows: {appDescription}.
13.1.7. An application/process has been updated in the TEP Marketplace
- event-type ID
-
appUpdated
- subscription filters
-
dataTypes (?)
- event properties
-
appUrl
appTitle
dataTypes(?)
??? - title template
-
The application called "{appTitle}" has been updated.
- body template
-
The application called "{appTitle}" has been updated to <a href={appUrl}>a new version<a>.
13.1.8. An application/process has been removed from the TEP Marketplace
- event-type ID
-
appRemoved
- subscription filters
-
dataTypes (?)
- event properties
-
appTitle
dataTypes(?)
??? - title template
-
The application called "{appTitle}" has been removed.
- body template
-
The application called "{appTitle}" has been removed. [TBD…]
13.1.9. A data set has been added as a TEP-holding
- event-type ID
-
dataSetAdded
- subscription filters
-
areaOfInterest (to check for intersection with bbox)
dataTypes(?) - event properties
-
fsetName
fsetTitle
fsetDescription
bbox
dataTypes(?)
dataSetUrl - title template
-
A new data set called "{fsetTitle}" is now available.
- body template
-
A new data set called "{fsetTitle}" (with a feature-set name of "{fsetName}") is now <a href="dataSetUrl">available<a>. It covers the spatial area of {bbox} and its description is as follows: {fsetDescription}.
13.1.10. A TEP-holding data set has been updated
- event-type ID
-
dataSetUpdated
- subscription filters
-
areaOfInterest (to check for intersection with bbox)
dataTypes(?) - event properties
-
fsetName
fsetTitle
bbox (of changed area)
dataTypes(?)
dataSetUrl - title template
-
The "{fsetTitle}" data set is has been updated.
- body template
-
The data set called "{fsetTitle}" (with a feature-set name of "{fsetName}") has been updated to <a href={dataSetUrl}>a new version<a>. The spatial area that has been affected is {bbox}.
13.1.11. A data set has been removed as a TEP-holding
- event-type ID
-
dataSetRemoved
- subscription filters
-
areaOfInterest (to check for intersection with bbox)
dataTypes(?) - event properties
-
fsetName
fsetTitle
bbox (of full data set prior to removal)
dataTypes(?) - title template
-
The "{fsetTitle}" data set is has been removed.
- body template
-
The data set called "{fsetTitle}" (with a feature-set name of "{fsetName}") has been removed. Its spatial area was {bbox}.
13.1.12. A new TEP-holdings web service is available
- event-type ID
-
webServiceAdded
- subscription filters
-
areaOfInterest (to check for intersection with bbox)
dataTypes(?) - event properties
-
fsetName
fsetTitle
fsetDescription
bbox
dataTypes(?)
dataSetUrl
webServiceUrl (the OGC API collections/{collectionId} endpoint?) - title template
-
A web service serving the data set called "{fsetTitle}" is now available.
- body template
-
A web service serving the data set called "{fsetTitle}" (with a feature-set name of "{fsetName}") is now available. It covers the spatial area of {bbox} and its description is as follows: {fsetDescription} The OGC API collection endpoint of this web service is: {webServiceUrl}
13.1.13. The data set served by a TEP-holdings web service has been updated
- event-type ID
-
webServiceUpdated
- subscription filters
-
areaOfInterest (to check for intersection with bbox)
dataTypes(?) - event properties
-
fsetName
fsetTitle
bbox (of changed area)
dataTypes(?)
dataSetUrl
webServiceUrl (the OGC API collections/{collectionId} endpoint?) - title template
-
The web service serving the data set called "{fsetTitle}" is has been updated.
- body template
-
The web service serving the data set called "{fsetTitle}" (with a feature-set name of "{fsetName}") has been updated to <a href={webServiceUrl}>a new version<a>. The spatial area that has been affected is {bbox}.
13.1.14. A TEP-holdings web service is no longer available
- event-type ID
-
webServiceRemoved
- subscription filters
-
areaOfInterest (to check for intersection with bbox)
dataTypes(?) - event properties
-
fsetName
fsetTitle
bbox (of full spatial area covered prior to removal)
dataTypes(?) - title template
-
The web service serving the data set called "{fsetTitle}" is no longer available.
- body template
-
The web service serving the data set called "{fsetTitle}" (with a feature-set name of "{fsetName}") is no longer available. Its spatial area was {bbox}.
13.1.15. Another TEP user has shared a new web service with the user
- event-type ID
-
sharedWebServiceAdded
- subscription filters
-
username (automatically applied; i.e., not a GUI option)
(to be compared with sharedWith; sharedWith==NULL matches all)
owner (username of TEP user doing the sharing)
areaOfInterest (to check for intersection with bbox)
dataTypes(?) - event properties
-
owner (username of TEP user doing the sharing)
ownerName (full name of TEP user doing the sharing)
sharedWith (specific user that’s granted access, or NULL for all)
fsetName
fsetTitle
fsetDescription
bbox
dataTypes(?)
dataSetUrl
webServiceUrl (the OGC API collections/{collectionId} endpoint?) - title template
-
User {owner} has shared a web service that serves a data set called "{fsetTitle}".
- body template
-
User {owner} ({ownerName}) has shared a web service that serves a data set called "{fsetTitle}" (with a feature-set name of "{fsetName}"). It covers the spatial area of {bbox} and its description is as follows: {fsetDescription} The OGC API collection endpoint of this web service is: {webServiceUrl}
13.1.16. The data set served by a shared web service has been updated
- event-type ID
-
sharedWebServiceUpdated
- subscription filters
-
username (automatically applied; i.e., not a GUI option)
(to be compared with sharedWith; sharedWith==NULL matches all)
owner (username of TEP user doing the sharing)
areaOfInterest (to check for intersection with bbox)
dataTypes(?) - event properties
-
owner (username of TEP user doing the sharing)
ownerName (full name of TEP user doing the sharing)
sharedWith (specific user that’s granted access, or NULL for all)
fsetName
fsetTitle
bbox (of changed area)
dataTypes(?)
dataSetUrl
webServiceUrl (the OGC API collections/{collectionId} endpoint?) - title template
-
The web service shared by user {owner} that serves a data set called "{fsetTitle}" has been updated.
- body template
-
The web service shared by user {owner} ({ownerName}) that serves a data set called "{fsetTitle}" has been updated to <a href={webServiceUrl}>a new version<a>. The spatial area that has been affected is {bbox}.
13.1.17. Another TEP user has stopped sharing a web service with the user
(Note: This event should also occur (with sharedWith=NULL) if the TEP user doing the sharing is removed.)
- event-type ID
-
sharedWebServiceRemoved
- subscription filters
-
username (automatically applied; i.e., not a GUI option)
(to be compared with sharedWith; sharedWith==NULL matches all)
owner (username of TEP user doing the sharing)
areaOfInterest (to check for intersection with bbox)
dataTypes(?) - event properties
-
owner (username of TEP user doing the sharing)
ownerName (full name of TEP user doing the sharing)
sharedWith (specific user whose access is being revoked, or NULL for all)
fsetName
fsetTitle
bbox (full spatial area covered prior to removal)
dataTypes(?) - title template
-
User {owner} has stopped shared the web service that serves a data set called "{fsetTitle}".
- body template
-
User {owner} ({ownerName}) has stopped sharing the web service that serves a data set called "{fsetTitle}" (with a feature-set name of "{fsetName}"). Its spatial area was {bbox}.
13.2. Notification methods
A potential set of notification methods is:
-
e-mail
-
SMS
-
webhook
-
process execution
-
news feed (visible from the TEP Marketplace web page)
-
RSS or Atom feed
For the first version of the TEP Marketplace, we will probably support only e-mail and the news feed.
Certain notification types (notably for workspace quotas and job activity) are for a user’s own events. Users should be automatically subscribed to receive such notifications through their news feed.
13.2.1. Subscription mechanism
The subscription mechanism should allow a user to view the list of the notifications that they’re currently subscribed to and:
-
subscribe to a notification
-
unsubscribe from a notification
-
pause or resume a subscription
-
edit the filters or notification methods of an existing subscription
The subscription mechanism would likely be based on OGC’s pub/sub standard.
13.3. Database tables
The following MariaDB database tables (in the cw_tep database) can be used to record the events that occur in the TEP Marketplace.
CREATE TABLE events (
event_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
event_type ENUM('quotaWarning1',
'quotaWarning2',
'quotaExceeded',
'jobCompleted',
'jobFailed',
'appAdded',
'appUpdated',
'appRemoved',
'dataSetAdded',
'dataSetUpdated',
'dataSetRemoved',
'webServiceAdded',
'webServiceUpdated',
'webServiceRemoved',
'sharedWebServiceAdded',
'sharedWebServiceUpdated',
'sharedWebServiceRemoved')
CHARACTER SET latin1 NOT NULL
) CHARACTER SET utf8 COLLATE utf8_bin;
CREATE TABLE event_properties (
event_id BIGINT UNSIGNED NOT NULL,
key VARCHAR(255) NOT NULL,
value TEXT NOT NULL,
FOREIGN KEY (event_id) REFERENCES events (event_id)
ON DELETE CASCADE ON UPDATE CASCADE
) CHARACTER SET utf8 COLLATE utf8_bin;Whenever an event record is read from the database, a corresponding read from the event_properties table should also be performed WHERE event_id={eventId} in order to determine the full set of property values for that event.
Event records will always be added, never deleted. In a future version of the TEP Marketplace, it may be worthwhile to add an event_summaries table that provides long-term summary information (similar to the request_summaries and served_summaries tables of the cw_audit database). It may also be necessary to cull the events table (but not the event_summaries table!) after so many records or months to keep it from growing too large.
The following MariaDB database tables (in the cw_tep database) can be used to keep track of the current subscriptions:
CREATE TABLE subscriptions (
subscription_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
created_at TIMESTAMP NOT NULL DEFAULT '1970-01-02',
updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP,
is_active BOOLEAN NOT NULL DEFAULT TRUE;
username VARCHAR(255) NOT NULL,
event_type ENUM('quotaWarning1',
'quotaWarning2',
'quotaExceeded',
'jobCompleted',
'jobFailed',
'appAdded',
'appUpdated',
'appRemoved',
'dataSetAdded',
'dataSetUpdated',
'dataSetRemoved',
'webServiceAdded',
'webServiceUpdated',
'webServiceRemoved',
'sharedWebServiceAdded',
'sharedWebServiceUpdated',
'sharedWebServiceRemoved')
CHARACTER SET latin1 NOT NULL,
methods VARCHAR(255) # comma-separated list of 'feed', 'e-mail', etc.?
FOREIGN KEY (username) REFERENCES cw_auth.users (username)
ON DELETE CASCADE ON UPDATE CASCADE
) CHARACTER SET utf8 COLLATE utf8_bin;
CREATE TABLE subscription_filters (
subscription_id BIGINT UNSIGNED NOT NULL,
key VARCHAR(255) NOT NULL,
value TEXT NOT NULL,
FOREIGN KEY (subscription_id) REFERENCES subscriptions (subscription_id)
ON DELETE CASCADE ON UPDATE CASCADE
) CHARACTER SET utf8 COLLATE utf8_bin;Whenever a subscription record is read from the database, a corresponding read from the subscription_filters table should also be performed WHERE subscription_id={subscriptionId} in order to determine the full set of filters for that subscription.
The events and subscriptions tables can be JOINed with the cw_auth.users table to determine the user’s full name and e-mail address, etc.
TBD: Do we need another table to keep track of every notification that’s sent?
13.4. Event Occurrences
The adding of an event to the events table should be done as low-level in the code as possible to reduce code duplication and to limit the number of execution paths which fail to trigger the appropriate event notifications. In Javascript this function call might look like:
eventOccurred("quotaWarning1",
{ "username": "bob",
"currentNumOfMBytes": "375.2",
"quotaNumOfMBytes": "500"});and in C this function call might look like:
err = CwTep_EventOccurred("quotaWarning1",
"username", "bob",
"currentNumOfMBytes", "375.2"
"quotaNumOfMBytes", "500",
NULL);Either way, all these functions do is add an entry to the events table (with the appropriate entries to the event_properties table).
Note that it may be a bit tricky to properly handle the quotaWarning1, quotaWarning2 and quotaExceeded events. Such events should only occur when the corresponding threshold is crossed to avoid bombarding the user with redundant warnings.
13.5. Notification Daemon
A notification daemon will be constantly running, and will wake up every few seconds to deliver the latest batch of subscribed-to event notifications. Its algorithm will look something like this:
every few seconds
newEvents = all events where created_at > lastPoll
lastPoll = now()
for each event in newEvents
for each subscription in subscriptions
if subscription.event_type == event.event_type
if subscription filters match event properties
for each subscription notification method (other than 'feed')
send out the appropriate notificationThe feed notification method will be handled differently. It will make use of the Atom feed.
14. Atom feed
Each TEP Marketplace user will have their own Atom feed. When a user makes a request to their Atom feed, the service providing that feed will read the events table directly to provide the latest feed items.
The news feed will make use of this Atom feed. The user may also make direct use of this feed.
14.1. Possibility of using third-party notification manager
Much of the above assumes that we will be building our own notification system from scratch. However, there’s still the possibility that there’s a third-party solution out there that we can make use of. Amazon EventBridge and Apache Kafka may be possibilities.
15. Analytics module
There needs to be a way to keep track of job history for analytics purposes. The information relevant for such a history is very similar to the information that the WPS needs to keep track of for active jobs, so it makes sense to use the same database table for both. (This would obsolete the status.json file that the WPS currently uses to keep track of such things.) This table should be in the cw_tep database, and should look something like this:
CREATE TABLE jobs (
id VARCHAR(255) PRIMARY KEY,
client_ip_address VARCHAR(45), # NULL if unknown
username VARCHAR(255), # key into cw_auth DB, NULL if none
execute_request LONGTEXT NOT NULL,
footprint_wgs84 GEOMETRY, # NULL if unknown or n/a
status ENUM('accepted','running','successful','failed',dismissed')
CHARACTER SET latin1 NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
started_at TIMESTAMP,
finished_at TIMESTAMP,
updated_at TIMESTAMP,
progress DOUBLE NOT NULL DEFAULT 0, # 0 until started ... 100 when finished
exception_report TEXT, # a JSON-encoded exception report, or NULL
# filled in once finished
duration DOUBLE NOT NULL, # real time in seconds
cpu_seconds DOUBLE NOT NULL, # CPU time in seconds
max_mem_used BIGINT NOT NULL DEFAULT 0, # number of bytes
bytes_staged_in BIGINT NOT NULL DEFAULT 0, # do we need this?
bytes_staged_out BIGINT NOT NULL DEFAULT 0, # do we need this?
stage_in_time DOUBLE NOT NULL DEFAULT 0, # number of seconds
stage_out_time DOUBLE NOT NULL DEFAULT 0, # number of seconds
# indexes
INDEX created_at_index (created_at),
INDEX username_index (username)
) CHARACTER SET utf8 COLLATE utf8_bin;This table will be automatically maintained by the WPS itself. Records will always be added, never deleted.
The information in this table will be used in at least three ways:
-
By the WPS to collect the information necessary to prepare the response of a
/jobsor/jobs/{jobId}request. -
By the TEP Marketplace to present the user with the list of their current job and their statuses.
-
By the TEP Marketplace Analytics tool (for administrators) to list the full history of jobs, allowing sorting and filtering on the various fields and providing reports, etc. TBD: Will the first version of the TEP Marketplace include such a tool?
In a future version of the TEP Marketplace, it may be worthwhile to add a job_summaries table that provides long-term summary information (similar to the request_summaries and served_summaries tables of the cw_audit database). It may also be necessary to cull the jobs table (but not the job_summaries table!) after so many records or months to keep it from growing too large.
16. Workflows and chaining
16.1. Overview
The TEP will initially be deployed with a set of built-in processes. Over time, more processes will be added by users. Eventually, users will want to chain one or more of these offered processes into a workflow in order to accomplish some task. This clause describes the chaining and workflow capabilities of the TEP.
The TEP shall implement the OGC Modular Workflows (MOAW) extension to the OGC API - Processes - Part 1: Core standad and shall also support the Common Workflow Language (CWL) as the means of expressing workflows.
The MOAW extension is not an OGC standard but CubeWerx is actively involved in the development of this standard and input from this projects shall be fed into that effort.
CWL is developed by a multi-vendor working group consisting of organizations and individuals aiming to enable scientists to share data analysis workflows.
16.2. OGC Modular Workflows
16.2.1. Overview
MOAW is an extension to the execute request defined the the OGC API - Processes - Part1: Core standard. MOAW defines four specific extensions to the execute request:
-
the ability to specify the output of one process as the input of another process
-
the ability to specify an OGC API collection as an input to a process
-
the ability to indicate that processing results should be published as an OGC API collection
-
the ability to indicate that processing results should be published as a complete OGC API endpoint (i.e. an OGC API landing page)
A MOAW workflow can be execute in an ad-hoc manner or it can be parameterized and deployed to the TEP as yet another process available for execution.
A MOAW workflow can also invoke a remote process as long as a trust agreement between the TEPs has been a priori established.
A MOAW workflow can also access remote collections.
16.2.2. Nested processes
The MOAW extension supports chaining of processes by allowing the output of one process to be the input of another process. This is expressed in an execute request by allowing the value of an input parameter to be a nested call to another processes whose result is the chained input value.
The understand the extension, consider the following example ADES process description. This process description defines a process that adds two numbers.
{
"id": "Add",
"title": "Add",
"description": "This process adds two numeric inputs",
"version": "1.0.0",
"jobControlOptions": [ "sync-execute" ],
"outputTransmission": [ "value" ],
"inputs": {
"value1": {
"title": "First Operand",
"schema": {
"type": "number"
}
},
"value2": {
"title": "Second Operand",
"schema": {
"type": "number"
}
}
},
"outputs": {
"result": {
"schema": {
"type": "number"
}
}
}
}Also consider the description of another ADES process that multiplies two numbers.
{
"id": "Mul",
"title": "Multiply",
"description": "This process multiplies two numeric inputs",
"version": "1.0.0",
"jobControlOptions": [ "sync-execute" ],
"outputTransmission": [ "value" ],
"inputs": {
"value1": {
"title": "First Operand",
"schema": {
"type": "number"
}
},
"value2": {
"title": "Second Operand",
"schema": {
"type": "number"
}
}
},
"outputs": {
"result": {
"schema": {
"type": "number"
}
}
}
}The following execute request can be used to multiply two numbers 10.2 and 13.5.
{
"inputs": {
"value1": 10.2,
"value2": 13.5
}
}The following execute request uses the MOAW extension to evaluate the expression 10.2 x (3.14+10.36). The nested call to the Add process adds the numbers 3.14 and 10.36. That result of that operation and then passed as the value of the value2 input to the Mul process which then multiplies 10.2 with 13.5 (the sum of 3.14 and 10.36) to generate the final result.
{
"inputs": {
"value1": 10.2,
"value2": {
"process": "Add",
"inputs": {
"value1": 9.2,
"value2": 4.3
}
}
}
}If the Add process was a remote process, the value of the process parameter in the above execute request would be a URI referencing the remote Add process deployed on abother TEP as illustrated in the following example:
{
"inputs": {
"value1": 10.2,
"value2": {
"process": "http://www.someotherserver.com/processes/Add",
"inputs": {
"value1": 9.2,
"value2": 4.3
}
}
}
}So far the example workflow has been executed in an adhoc manner. That means that the workflow was POSTed to the ADES, executed and the response presented to the calling entity.
This workflow, however, could also be parameterized and deployed to the ADES as just another process that can be invoked by a user. The following application package illustrates how this workflow itself could be specified as the execution unit of the new process identified as MulAdd:
{
"processDescription": {
"process": {
"id": "MulAdd",
"title": "Add and Multiply",
"description": "This process adds the first two numeric inputs and then multiplies the result by a third input.",
"version": "1.0.0",
"jobControlOptions": [ "sync-execute" ],
"outputTransmission": [ "value" ],
"inputs": {
"value1": {
"title": "First Addend (add)",
"schema": {
"type": "number"
}
},
"value2": {
"title": "Second Addend (add)",
"schema": {
"type": "number"
}
},
"value3": {
"title": "The Multiplicand (mul)",
"schema": {
"type": "number"
}
}
},
"outputs": {
"result": {
"schema": {
"type": "number"
}
}
}
}
},
"executionUnit": {
"type": "moaw",
"source": {
"process": "Mul",
"inputs": {
"value1": { "input": "value3" },
"value2": {
"process": "Add",
"inputs": {
"value1": { "input": "value1" },
"value2": { "input": "value2" }
}
}
}
}
}
}The structure {"input": …} is used to indicate how the inputs in the definition of the new process are mapped to parameters in the workflow. In this case, the input parameters value1 and value2 are mapped as arguments to the Add process and the parameter value2 is mapped to the first multiplicand parameter of the Mul process.
Using this application package text as the body of a HTTP POST request to the /processes endpoint of the ADES would deploy this workflow as an executables process on the TEP.
The following request illustrates how to execute this newly deployed MulAdd process.
{
"inputs": {
"value1": 10.2,
"value2": 9.2,
"value3": 4.3
}
}This invocation would add the values 9.2 and 4.3 and then multiply the result by 10.2.
16.3. Common Workflow Language
Common Workflow Language (CWL) is an open standard for describing how to run application and connect them to create workflows. This clause discusses the details of the integration of CWL into the TEP environment.
A CWL script is file that is interpreted and executed by a runner. A runner is simply an application that knows how to parse and execute a CWL script. There are many implementations of CWL runners listed here https://www.commonwl.org/implementations/.
For the TEP, the chosen runner shall be bundled into a Docker container. Whenever a CWL workflow is presented to the ADES, that Docker container will be executed to process the workflow. Although CWL is a generic workflow processing engine, for the TEP, CWL will be used to combine TEP process invocations into workflows.
Using the same multiply-add example as presented above, the following CWL file will execute a workflow that multiplies two number (using the "Mul" process) and add the result to a third number (using the "Add" process).
cwlVersion: v1.0
$graph:
class: Workflow
label: MulAdd
doc: This application adds two numbers and multiplies the result by a third.
id: muladd
inputs:
value1:
type: double
label: value1
doc: The multiplicand.
value2:
type: double
label: value2
doc: First addend.
value3:
type: double
label: value3
doc: Second addend.
outputs:
result:
type: double
label: result
steps:
add:
run: "Add"
in:
value1: value2
value2: value3
out: add_result
mul:
run: "Mul"
in:
value1: value1
value2: add_resultThis ad-hoc workflow could, as was the case in the above example, be deployed as a persistent process using the same application package as that used above. The only difference would be that the executionUnit would be CWL in this case rather the OGC Modular Workflow used in the above example.
{
"processDescription": {
"process": {
"id": "MulAdd",
"title": "Add and Multiply",
"description": "This process adds the first two numeric inputs and then multiplies the result by a third input.",
"version": "1.0.0",
"jobControlOptions": [ "sync-execute" ],
"outputTransmission": [ "value" ],
"inputs": {
"value1": {
"title": "First Operand (add)",
"schema": {
"type": "number"
}
},
"value2": {
"title": "Second Operand (add)",
"schema": {
"type": "number"
}
},
"value3": {
"title": "Third Operand (mul)",
"schema": {
"type": "number"
}
}
},
"outputs": {
"result": {
"schema": {
"type": "number"
}
}
}
}
},
"executionUnit": {
"type": "cwl",
"unit": {
"cwlVersion": "v1.0",
"class": "Workflow",
"inputs": {
"value1": "double",
"value2": "double",
"value3": "double"
},
"outputs": {
"output": {
"type": "double",
"outputSource": "mul/output"
}
},
"steps": {
"add": {
"run": "path/to/file/add.cwl",
"in": {
"add1": "value2",
"add2": "value3"
},
"out": [
"output"
]
},
"mul": {
"run": "path/to/file/mul.cwl",
"in": {
"mul1": "value1",
"mul2": "add/output"
},
"out": [
"output"
]
}
}
}
}
}17. The OGC Application Package
17.1. Overview
In order to deploy an application to the TEP, the application must be defined in an application package. An application package is a JSON document that contains the description of the application; that is the definition of the application’s inputs, outputs and the execution unit for the application. The application package may also contains additional metadata about the resources required by the execution unit (e.g. number of CPUs, memory requirements, disk space requirements, GPU access, etc.).
17.2. OGC Application Package schema
17.2.1. Overview
The following YAML fragment defines the schema of an application package.
type: object
required:
- executionUnit
properties:
processDescription:
$ref: code/openapi/schemas/process.yaml
executionUnit:
description: |
Resource containing an executable or runtime information for executing
the process.
type: array
minItems: 1
items:
type: object
required:
- type
properties:
type:
type: string
description: |
The type of executable unit. Right now there is no defined
vocabulary of types. Common terms might include "docker",
"python", "cwl".
example:
type: docker
unit:
type: string
description: |
How this value is interpreted depends on the value of the "type"
parameter. If the value of "type" is "docker", for example, then
the value of the "unit" parameter would be a reference to a
container (e.g. pvretano/ndvi:latest). If the value of the "type"
is "cwl" then the value of this parameter could be the text of the
CWL script or a URI that resolves to the text of the script.
config:
type: object
description: |
Hardware requirements and configuration properties for executing
the process.
properties:
cpuMin:
description: |
Minimum number of CPUs required to run the process (unit is
CPU core).
type: number
minValue: 1
cpuMax:
description: |
Maximum number of CPU dedicated to the process (unit is CPU
core)
type: number
memoryMin:
description: |
Minimum RAM memory required to run the application (unit is GB)
type: number
memoryMax:
description: |
Maximum RAM memory dedicated to the application (unit is GB)
type: number
storageTempMin:
description: |
Minimum required temporary storage size (unit is GB)
type: number
storageOutputsMin:
description: Minimum required output storage size (unit is GB)
type: number
jobTimeout:
description: Timeout delay for a job execution (in seconds)
type: number
additionalProperties: true
additionalProperties: true
example:
type: docker
image: mydocker/ndvi:latest
config:
cpuMin: 2
cpuMax: 5
memoryMin: 1
memoryMax: 317.2.2. processDescription property
The formal process description (i.e. its inputs, its output, etc.) is provided, either in-line using the processDescription property or may be inferred from the information provided in the execution unit. The value of the processDescription property shall be based upon the OpenAPI 3.0 schema process.yaml.
17.2.3. executionUnit property
The execution unit is the code that the ADES needs to execute whenever the deployed process is executed through the OGC processes API . The execution unit can be either specified in-line (e.g. a CWL script) or by reference (e.g. a docker image reference). The following example of a NDVI calculating process specified a docker container as the execution unit.
{
"processDescription": {
"id": "NdviCalculation",
"title": "Calculation of NDVI using the SNAP toolbox for Sentinel-2",
"description": "Calculation of NDVI using the SNAP toolbox for Sentinel-2",
"version": "1.0.0",
"keywords": [
"Vegetation",
"NDVI"
],
"inputs": [
{
"id": "source",
"title": "Source Input Image (sentinel-2 product in SAFE format)",
"description": "Source Input Image (sentinel-2 product in SAFE format). Either provided inline, by reference or by product ID",
"minOccurs": 1,
"maxOccurs": 1,
"schema": {
"oneOf": [
{
"type": "string",
},
{
"type": "string",
"format": "uri"
},
{
"type": "string",
"contentEncoding": "base64",
"contentMediaType": "application/zip"
}
]
},
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "prefix",
"values": ["sourceImage"]
},
{
"name": "argumentSeparator",
"values": ["="]
}
]
}
]
},
{
"id": "red_source_band",
"title": "the band to be used for the red band",
"minOccurs": 0,
"maxOccurs": 1,
"schema": {
"type": "integer",
"minimumValue": 1,
"maximumValue": 13,
"rangeClosure": "closed"
},
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "prefix",
"values": ["red_band"]
},
{
"name": "argumentSeparator",
"values": ["="]
}
]
}
]
},
{
"id": "nir_source_band",
"title": "the band to be used for the near-infrared band",
"minOccurs": 0,
"maxOccurs": 1,
"schema": {
"type": "integer",
"minimumValue": 1,
"maximumValue": 13,
"rangeClosure": "closed"
},
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "prefix",
"values": ["nir_band"]
},
{
"name": "argumentSeparator",
"values": ["="]
}
]
}
]
},
{
"id": "red_factor",
"title": "the factor of the NRI",
"minOccurs": 0,
"maxOccurs": 1,
"schema": {
"type": "number",
"default": 1.0
"minimumValue": 0.0
},
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "prefix",
"values": ["red_factor"]
},
{
"name": "argumentSeparator",
"values": ["="]
}
]
}
]
},
{
"id": "nir_factor",
"title": "the factor of the NIR",
"minOccurs": 0,
"maxOccurs": 1,
"schema": {
"type": "number",
"default": 1.0
"minimumValue": 0.0
},
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "prefix",
"values": ["nir_factor"]
},
{
"name": "argumentSeparator",
"values": ["="]
}
]
}
]
},
{
"id": "cloud_coverage",
"title": "The cloud coverage of the scene.",
"minOccurs": 0,
"maxOccurs": 1,
"schema": {
"type": "integer",
"minimumValue": 0
"maximumValue": 100,
"rangeClosure": "closed"
},
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "prefix",
"values": ["cc"]
},
{
"name": "argumentSeparator",
"values": ["="]
}
]
}
]
},
{
"id": "max_cloud_coverage",
"title": "The maximum cloud coverage of the scene.",
"minOccurs": 0,
"maxOccurs": 1,
"schema": {
"type": "integer",
"minimumValue": 0
"maximumValue": 100,
"rangeClosure": "closed"
},
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "prefix",
"values": ["max_cc"]
},
{
"name": "argumentSeparator",
"values": ["="]
}
]
}
]
}
],
"outputs": [
{
"id": "raster",
"title": "The raster of the resulting NDVI calculation",
"schema": {
"type": "string",
"contentEncoding": "binary",
"contentType": "image/tiff; application=geotiff"
}
}
]
},
"jobControlOptions": [
"async-execute"
],
"outputTransmission": [
"value"
"reference"
],
"executionUnit": [
{
"type": "docker",
"unit": "eoc/ndvi:latest",
"config": {
"cpuMin": 2
}
}
]
}17.2.4. Additional parameters
The additionalParameters member is used to specify additional processing instructions for the nearest-to-scope entity in the application package. Processing instructions fall into three categories: binding directives, processing directives and client hints or rendering directives.
The schema of the additionalParameters member is:
allOf:
- $ref: "metadata.yaml"
- type: object
properties:
parameters:
type: array
items:
$ref: "additionalParameter.yaml"type: object
properties:
title:
type: string
role:
type: string
href:
type: stringtype: object
required:
- name
- value
properties:
name:
type: string
value:
type: array
items:
oneOf:
- type: string
- type: number
- type: integer
- type: array
items: {}
- type: objectEach additional parameter is an object with a role member and a parameters member.
The role member indicates the role of the parameters in the parameters member. Three roles are defined for the CSA project as specified in the following table.
| Role name | Description |
|---|---|
inputBinding |
Indicates how arguments from a process description are mapped to arguments for the execution unit. |
processingDirectives |
Provides processing hints to the nearest-to-scope entity. For example, a process input with cardinality greater than 1 can be processed in parallel. |
clientHints |
Provides rendering hints for client applications that use the application package information for generating dynamic input forms. |
The parameters member is an array of parameter objects, each related to the specified role.
Input binding role
In order to be able to invoke the execution unit, the ADES needs to know how the inputs defined in the process description are mapped to arguments in the execution unit. Arguments can be passed to the execution unit in a number of way including: positionally; of the form -argument value; of the form argument=value; etc. The input binding directives indicate how the ADES should map process input to execution units arguments.
The following example of the additionalParameters member illustrates that process input are passed as arguments to the execution unit using the form argument=value.
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "prefix",
"values": ["cc"]
},
{
"name": "argumentSeparator",
"values": ["="]
}
]
}
]In this example, the cloud cover input (i.e. cc) would be mapped to the execution unit as cc=value.
The following table defines the parameters for the inputBinding role.
| Parameter name | Datatype | Default | Description |
|---|---|---|---|
loadContents |
boolean |
false |
Indicates that the value of this argument is a file name or reference and should be staged for the application by the ADES. |
loadListing |
boolean |
false |
Indicates that the value of this argument is a directory name or reference. The directory should be staged for the application by the ADES. |
position |
integer |
0 |
The sorting key for positionally specified arguments |
prefix |
string |
N/A |
Command line prefix to add before the argument value. |
argumentSeparator |
string |
N/A |
Specifies the character that should be used to separate an argument from its value on the command line. |
separate |
boolean |
true |
If the argument is an array of values this parameter indicates whether the argument can be repeated on the command line OR whether the values should be concatenated into a single string. |
itemSeparator |
string |
"," |
Used with the |
shellQuote |
boolean |
true |
Indicates whether the argument value should be quoted on the command line. |
Processing directive
Processing directives are special processing hints for the nearest-to-scope entity. For example, consider an input that has a cardinality greater than 1 and an execute request that specifies multiple values for that input. By default an ADES has no way of knowning whether these multiple inputs are correlated or independent. If they are correlated then they cannot be processes in parallel. If they are independent, however, the ADES can decide to spawn N parallel executions of the process each handling one (or a batch) of the multiple input values.
The following tables defines the parameters for the processingDirective role.
| Parameter name | Datatype | Default | Description |
|---|---|---|---|
correlatedInputs |
boolean |
false |
For an input with cardinality greater than 1 indicates whether the input values are correlated or not. |
Client hints role
Client hints are used to embed hints about how a rendering client should present the nearest-to-scope entity. For example, a client hint can be used to indicate that a specific input should be rendered as a select list in an HTML page.
The following table defines the parameters for the clientHints role.
| Client hint name | Datatype | Default | Description |
|---|---|---|---|
htmlInputType |
string |
N/A |
Indicate the type of HTML widget that should be used to render the input in a dynamic form (e.g. selectlist). |
18. Execution Management Service (EMS)
18.1. Overview
The EMS is the central, coordinating component of the TEP. Although a critical component in this architecture, it is not the subject of standardization efforts currently, since all of the other components that it interacts with already provide standard or emerging standard interfaces. It could more properly be considered an application, built around the components of the TEP, to tie them all together. It is responsible for:
-
Providing the back end of the EMS Web Client, and generating the front end
-
Interacting with the catalogue to handle search capabilities
-
Composing application packages and posting them to the Docker Registry Service and the ADES
-
Registering developer-supplied packages in the catalogue
-
Invoking deployed applications in the ADES
-
Handling notifications from the ADES regarding job statuses
-
Handling all notification services required to keep users appraised of the status of their jobs
-
Ensuring that identity tokens are correctly transmitted between upstream and downstream services
Given the nature of the EMS, we will cover it in less detail in this document than the components that publish public APIs or may need to integrate with other tools and systems. Its basic architecture will be described, as well as its interfaces with other components.
18.2. General Architecture
The EMS is being implemented in PHP, using the Slim Micro Framework (https://www.slimframework.com/) for its REST APIs and basic structure. PHP was chosen for its relatively complete set of packages and functionality required to handle the various interactions that will be necessary between other components (XML, ATOM, HTML/JavaScript, OpenSearch, AWS etc.).
All communication between the EMS and Amazon Web Services are handled either with Amazon’s PHP API, or directly from the system shell using PHP merely as a scripting language. Composer (https://getcomposer.org/ ) is used to manage 3rd party packages and libraries and keep them up to date.
18.3. Authentication and Access Control
Although the EMS Web Client will communicate directly with the Identity Token Service to authenticate and obtain valid credentials, the EMS back end will validate those credentials and insure that they are passed along to any downstream services in order to allow for proper access control. A secure token, in the form of an encrypted HTTP cookie, is attached to all back-channel Web Service requests executed by the EMS.
18.4. Search
All search functionality, both for data and for available applications are handled by an catalogue using the OpenSearch API. To enable proper discovery of imagery, the OpenSearch Time and Geo extensions are implemented by the catalogue. The EMS is responsible for formulating proper OpenSearch queries and processing the results for display by the Web Client.
18.5. Docker Registry
The EMS posts Docker images to the Amazon Docker registry on behalf of the client. Docker is manipulated using a set of command-line tools, but this complexity will be hidden from the user and taken care of on their behalf by the EMS client and server.
18.6. Web Client HTML Templates
The Slim Framework supports several templating packages to generate dynamic HTML. We are using the simple php-view package (https://github.com/slimphp/PHP-View) to render the web pages necessary for the EMS Web Client. This allows customization of the Web Client based on user credentials, to display a different interface for developers vs users, for instance.
18.7. ADES Interface
The Application Deployment and Execution Service (ADES) is responsible for execution of developers’ containers on the cloud service providers architecture. It provides a standard OGC API Processes (OAPIP) endpoint. The EMS communicates with the ADES via that protocol.
The EMS is responsible for constructing the appropriate WPS requests (as detailed in chapter 8 below) in order to deploy and execute applications, monitor their execution and deliver the results.
18.8. Notification Services
The normal method for monitoring execution of a process executed by a Web Processing Server is using a polling mechanism defined by the WPS standard, and the GetStatus operation. This is inefficient for long running jobs, for that reason the ADES implements a push notification mechanism based on the work done during OGC Testbed 12 and described in "Testbed-12 Implementing Asynchronous Services Response Engineering Report (see OGC 15-023r3, 7.2).
This allows the server to report to the client (the EMS) when a job has completed. The ADES sends its notifications to a Webhook as per http://www.webhooks.org implemented in the EMS. The EMS will then report to the client via email, SMS etc.
The ADES also implements the standard GetStatus operation, which may also be used in the Web Client to provide progress indicators etc. to the user.
19. Application Deployment and Execution Service (ADES)
19.1. Overview
This chapter describes the mechanism for the deployment and execution of applications built in the context of the TEP. The TEP refers to a computing platform that follows a given set of scenarios for users, data and ICT (Information and Communications Technology) provision aggregated around an Earth Science thematic area. The TEP defines three canonical user scenarios covering the EO data exploitation (users discover and manipulate data), new EO service development (users deploy a new processor) and new EO product development (users publish new results). The TEP implements these canonical scenarios and moves the processing to the data, rather than the data to the users, thereby enabling ultra-fast data access and processing.
Algorithms are initially developed by a third-party developer and subsequently deployed in the TEP as an application package. An application package contains all the information necessary to allow applications to be specified and deployed in federated resource providers.
The application package encoding conveys all the information needed for encapsulating user applications and enabling their automatic management (upload, deploy, run) in diverse platforms. The application package is described in detailed in the The OGC Application Package.
As ADES is an OGC API - Processes deployment that was been extended to accept an application package as input. The ADES processes the application package and deploys the process described therein. Once deployed, the process becomes part of the API of the ADES and can be invoked using an execute request.
In the TEP the application package is create by the EMS service, on behalf of developers. The execution unit of the application is then deployed on the TEP’s cloud infrastructure by the ADES. At that point, the application is ready to be executed on the TEP-holdings or the a TEP user’s workspace data.
19.2. Developer scenario
Referring to App Developer Scenario, the application package allows a developer (e.g. Marco) to register an application that will be deployed at a given cloud provider site. The application is first built and registered in a third-party Application Hub (e.g., DockerHub). The developer then directly interacts with the EMS Client that registers the application on the ADES.
The sequence of actions is described in the following sequence diagram image.
 Figure 4 - Sequence of Deploy and Register Steps
Figure 4 - Sequence of Deploy and Register Steps
With the application registered, a user (e.g., Jim) can directly interact with the EMS Client that will allow the execution of the application on the ADES.
The sequence of actions for the execution is described in the following sequence diagram image.
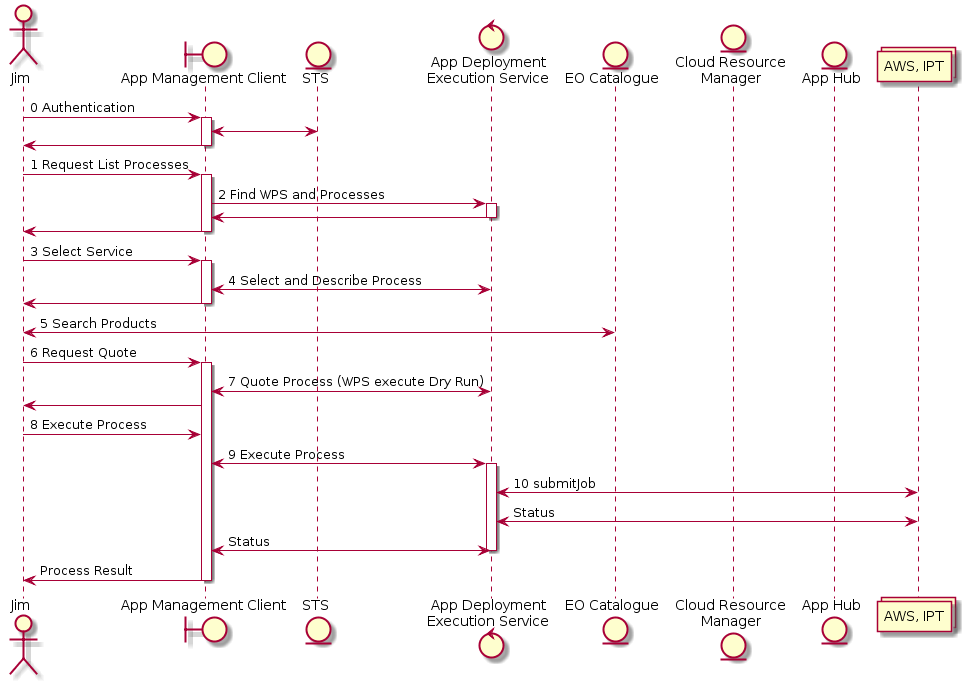 Figure 5 - Sequence of Execution Steps
Figure 5 - Sequence of Execution Steps
19.3. Deployment
The following diagram illustrates the process of deploying a user-defined application to an ADES.
Client Server
| |
| POST /processes HTTP/1.1 |
| Content-Type: application/ogcapppkg+json |
| |
| ... Body contains a formal description of the process to |
| add (e.g. OGC Application Package) ... |
|------------------------------------------------------------>|
| |
| HTTP/1.1 201 Created |
| Location: /processes/\{processID} |
| |
| ... The response body contains a process summary... |
|<------------------------------------------------------------|The request body contains an application package that is HTTP POSTed to the /processes endpoint of the ADES. The application package contains a machine-readable description of the process to be deployed. The ADES reads the application package, deploys the process and responds with the identifier (i.e. /process/{processID}) for the newly added process.
The following JSON fragment is an example of an application package.
{
"processDescription": {
"id": "dsi",
"title": "Ship Detection Process",
"abstract": "A Process that detects ships in SAR images and outputs the detections into various output file formats including GeoJSON. SAR images from RS2 , RCM and Sentinel-1 are supported.",
"inputs": [
{
"id": "productRef",
"title": "SAR Product Reference",
"abstract": "A reference to a SAR product.",
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "position",
"values": ["1"]
},
{
"name": "valueForm",
"values": ["parameterFile"]
}
]
},
{
"role": "clientHint",
"parameters": [
{
"name": "htmlInputType",
"value": "file"
}
]
}
],
"formats": [{"mimeType": "application/directory"}],
"minOccurs": "1",
"maxOccurs": "unbounded"
}
],
"outputs": [
{
"id": "output",
"title": "Ship Locations",
"abstract": "Detected shop locations in GeoJSON.",
"formats": [{"mimeType": "application/geo+json"}],
"minOccurs": "1",
"maxOccurs": "1"
}
]
},
"jobControlOptions": [
"async-execute"
],
"outputTransmission": [
"reference"
],
"executionUnit": [
{
"type": "docker",
"unit": "pvretano/dsi:latest",
"config": {
"cpuMin": 4
}
}
]
}The following JSON fragment is an example of a process summary generated as the content of a deployment operation.
{
"processSummary": {
"id": "dsi",
"title": "Ship Detection Process",
"abstract": "A Process that detects ships in SAR images and outputs the detections into various output file formats including GeoJSON. SAR images from RS2, RCM and Sentinel-1 are supported.",
"processVersion": "1.0.0",
"jobControlOptions": [ "async-execute" ],
"outputTransmission": [ "reference" ],
"processDescriptionURL": "https://www.pvretano.com/cubewerx/cubeserv/default/ogcapi/wpstest/processes/dsi"
}
}19.4. Execution
The following diagram illustrates how a deployed process can be executed:
Client Server
| |
| POST /processes/dsi/jobs?responseHandler=mailto:person@email.com HTTP/1.1 |
| Content-Type: application/json |
| |
| ... Body contains a JSON-encoded execute request ... |
|-------------------------------------------------------------------------->|
| |
| HTTP/1.1 201 Created |
| Location: https://.../dsi/jobs/J001 |
| Content-Type: application/json; charset=UTF-8 |
| |
| ... The response body contains a JSON-encoded status... |
|<--------------------------------------------------------------------------|The body of the HTTP post is a JSON-encoded execute request. The following JSON fragment is an example of a JSON-encoded execute request:
{
"inputs": [
{
"id": "productRef",
"input": {
"format": { "mimeType": "application/directory" },
"value": { "href": "s3://.../RCM product/..." }
}
}
],
"outputs": [
{
"id": "output",
"transmissionMode": "reference"
}
],
"mode": "async",
"response": "document"
}19.5. Monitoring Execution
The normal workflow of executing an application includes using the GET operation at the /jobs/{jobID} endpoint to poll the server to determine the execution status of a running job. The server offers this polling method of monitoring the process BUT it also oofers a more efficient notification approach where the server notifies the client when the operation has completed processing.
The notification is triggered by specifying a value for the responseHandler parameter. The value of the response handler can be something like mailto:user@server.com or sms:4165555555. The details of the response handler parameter can be found in OGC 16-023r3, clause 7.2.
The value of any specified response handler is ignored by the ADES unless the value of the mode parameter is set to async indicating asynchronous execution. The response to an asynchronous request is a status information message such as the one shown below:
{
"jobId": "J001",
"status": "accepted",
"links": [
{
"href": "https://.../dsi/jobs/J001",
"rel": "monitor",
"type": "application/json"
}
]
}19.6. Error Handling
If an error occurs, the ADES will generate an exception report as shown below:
{
"type": "OgcApiExceptionReport",
"httpStatus": 500,
"details": [
{
"description": "A server-side exception has occurred"
},
{
"description": "undefined",
"traceInfo": {
"filename": "wpsOgcApi.c",
"function": "WpsOgcApi_HandleProcessIdPathElement",
"line": 393
}
},
{
"description": "Failed to parse JSON body from input stream",
"traceInfo": {
"filename": "wpsModule.c",
"function": "Wps_ExecuteREST",
"line": 563
}
}
]
}In this example, the execute request body was invalid.
19.7. Bindings
The following table summaries the resources implemented by the CubeWerx OAProc service:
| Resource path | Method | Description | Parameters | Response |
|---|---|---|---|---|
/ |
GET |
Get the server’s landing page. |
see here |
A JSON-encoded landing page. |
POST |
undefined |
|||
PUT |
undefined |
|||
DELETE |
undefined |
|||
/conformance |
GET |
Get the service’s conformance declaration. |
see here |
The list of OGC conformance classes the server implements. |
POST |
undefined |
|||
PUT |
undefined |
|||
DELETE |
undefined |
|||
/processes |
GET |
Get the list of processes offered by the server. |
see here |
A JSON-encoded document with a list of processes summaries. |
POST |
Deploy a new process to the server. |
Body contains an app package |
Empty with 201 HTTP status code. |
|
PUT |
undefined |
|||
DELETE |
undefined |
|||
/processes/{processID} |
GET |
Retrieve a detailed description of the process. |
see here |
Body contains a JSON-encoded process description. |
POST |
undefined |
|||
PUT |
undefined |
|||
DELETE |
Undeploy a previously deployed process. |
Empty body with 200 HTTP status code. |
||
/processes\/{processID}/execution |
GET |
undefined |
||
POST |
Execute a process. |
see here |
Body contains a JSON-encoded execute request. |
|
PUT |
undefined |
|||
DELETE |
undefined |
|||
/jobs |
GET |
Retrieve a list of job statuses. |
see here |
Body contains a JSON-encoded list of jobs. |
POST |
undefined |
|||
PUT |
undefined |
|||
DELETE |
undefined |
|||
/jobs/{jobId} |
GET |
Get a status report of the specified job. |
see here |
Body contains a JSON-encoded status info document. |
POST |
undefined |
|||
PUT |
undefined |
|||
DELETE |
Cancel or remove a job. |
see here |
Empty body with 200 HTTP status. |
|
The server also implements the OPTIONS method (see RFC2616, clause 9) which allows clients to ascertain the methods and representations that are supported for each resource.
The following sequence diagram illustrates the sequence of operations performed by the ADES on the back end to execute a deployed application.
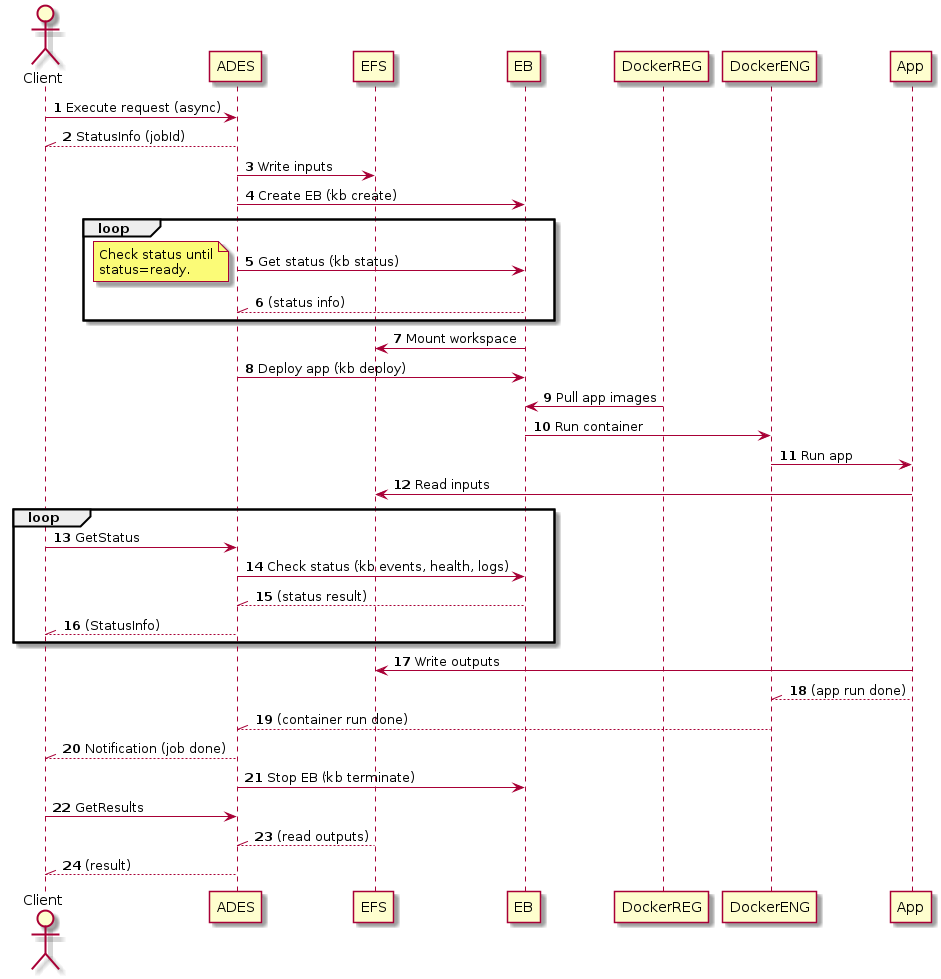 Figure 6 - Sequence Diagram for Application Execution
Figure 6 - Sequence Diagram for Application Execution
Keys:
-
ADES = Application Deployment and Execution Service
-
EFS = Elastic File System
-
EB = Elastic kuBernetes service
-
DockerREG = Docker registry
-
DockerENG = Docker engine
-
App = Application bundled in Docker image
19.8. Notifications
19.8.1. Overview
The OGC API - Processes standard defines a polling mechanism for monitoring the status of an executing process to determine when a job is complete. A more efficient approach would be to have the ADES push a notification to the client when the execution of a job has been completed.
For the TEP, the server will implement a push notification mechanism based on the work done during OGC Testbed 12 and described in "Testbed-12 Implementing Asynchronous Services Response Engineering Report (see OGC 15-023r3, 7.2).
NOTE: This capability is implemented in addition to the standard polling (i.e. GetStatus) approach defined in the OAProc standard.
19.8.2. ResponseHandler parameter
Push notification is triggered by the presence of the responseHandler parameter on a execute request. The following JSON-schema fragment defines the responseHandler parameter:
name: responseHandler
in: query
required: false
schema:
type: array
items:
type: string
format: url
style: form
explode: falseOne or more values may be specified for the responseHandler parameter. Each element of the list of values of the responseHandler shall be a URI. The form of the URI shall be a valid expression of one of the notification schemes that the server claims to support in its service description.
Possible nodiciation schemes include:
-
Email scheme as per RFC 2368
-
Example — mailto:tb12@pvretano.com
-
-
Sms scheme as per Apple Inc. (see RFC 5724)
-
Example – sms:1-555-555-5555
-
-
Webhook as per http://www.webhooks.org
-
Example — http://www.myserver.com/posthandler
-
Example:
The following example execute request shows the use of the responseHandler parameter:
POST /processes/dsi/execution?responseHandler=mailto:me@myemail.com,mailto:you@youremail.com19.8.3. Response
The response to a request that contains a responseHandler is the standard asynchronous status info response whose schema is shown in the following JSON-schema fragment:
type: object
required:
- jobID
- status
properties:
jobID:
type: string
status:
type: string
enum:
- accepted
- running
- successful
- failed
- dismissed
message:
type: string
progress:
type: integer
minimum: 0
maximum: 100
links:
type: array
items:
$ref: "code/openapi/schemas/link.yaml"This schema allows zero or more hypermedia controls (i.e. links) to be included in the response. Two "rel" values, rel="monitor" and rel="cancel" are used by the server to provide links that may be used to monitor the status of a job and links that may be used to cancel a job.
The following example shows the use of hypermedia control in the response to an Execute request:
{
"jobID": "J001",
"status": "running",
"links": [
{
"href": "http://.../dsi/jobs/J001?op=cancel",
"rel": "cancel"
},
{
"href": "http://www.someserver.com/some/opaque/endpoint",
"req": "monitor"
}
]
}In this case, the client may follow the rel="cancel" link to cancel the job and may use the rel="monitor" link to get the current status of a job. The advantage of using hypermedia controls is that the hypermedia controls are opaque thus relieving the client of having to know how to construct these URLs. All the clients need to know is how to interpret the rel value and how to follow links.
19.9. Parallel execution analyzer
In order to leverage the elasticity of the cloud infrastructure upon which the TEP is built, the ADES must analyze each execution request and determine the extent to which that execution can be parallelized. This analysis is performed using the description of the application and the inputs provided in the execute request. The process description can also include hints or directives to let the ADES know the certain aspects of the execution of a process can be parallelized.
For example, consider the following process description:
{
"id": "dsi",
"processVersion": "1.0.0",
"title": "Ship Detection Process",
"abstract": "A Process that detects ships in SAR images and outputs the detections into various output file formats including GeoJSON. SAR images from RS2, RCM and Sentinel-1 are supported.",
"jobControlOptions": ["async-execute"],
"outputTransmission": ["reference"]
"inputs": [
{
"id": "productRef",
"title": "SAR Product Reference",
"abstract": "A reference to a SAR product.",
"additionalParameters": [
{
"role": "inputBinding",
"parameters": [
{
"name": "position",
"values": ["1"]
},
{
"name": "valueForm",
"values": ["parameterFile"]
}
]
},
{
"role": "processingDirectives",
"parameters": [
{
"name": "correlatedInputs",
"values": [false]
}
]
},
{
"role": "clientHints",
"parameters": [
{
"name": "htmlInputType",
"value": ["file"]
}
]
}
],
"formats": [{"mimeType": "application/directory"}],
"minOccurs": "1",
"maxOccurs": "unbounded"
}
],
"outputs": [
{
"id": "output",
"title": "GeoJSON Output File",
"abstract": "",
"formats": [{"mimeType": "application/geo+json"}],
"minOccurs": "1",
"maxOccurs": "1"
}
]
}This processes takes a single input with an unlimited cardinality. Without any processing directives, the ADES cannot assume that N instances of this process can be executed in parallel if M inputs (M>=N) are specified in an execution request. This process description, however, includes a processing directive named correlatedInputs for the productRef input. This directive indicates that if multiple inputs are specified, they are not correlated or dependent on each other and so the ADES can decide to execute parallel instances of this process to speed up processing of all the provided inputs.
19.10. Periodic, scheduled or triggered execution
The schema for an execute request from OGC API - Processes - Part 1: Core is:
type: object
properties:
inputs:
additionalProperties:
oneOf:
- $ref: "inlineOrRefData.yaml"
- type: array
items:
$ref: "inlineOrRefData.yaml"
outputs:
additionalProperties:
$ref: "output.yaml"
response:
type: string
enum:
- raw
- document
default:
- raw
subscriber:
$ref: "subscriber.yaml"This schema shall be extended for the CSA project with a parameter named repeat as specified be the following schema:
type: object
properties:
inputs:
additionalProperties:
oneOf:
- $ref: "inlineOrRefData.yaml"
- type: array
items:
$ref: "inlineOrRefData.yaml"
outputs:
additionalProperties:
$ref: "output.yaml"
repeat:
type: string
format: date-time
response:
type: string
enum:
- raw
- document
default:
- raw
subscriber:
$ref: "subscriber.yaml"The value of the repeat parameter is an ISO8601 date-time string. The value can be a time instant or a recurring time interval. If the value of the repeat parameter is a time instant in the future then the process shall be queued for execution at that time; otherwise the time instant value is ignored. If the value of the repeat parameter is a recurring time interval then the process is executed and re-executed at each repeating interval.
The following example illustrates an execute request, using the dsi process described above, that is automatically re-executed once a week by the ADES. This is specified using the repeat parameter with a value of P1W.
{
"inputs": [
{
"id": "productRef",
"input": {
"format": { "mimeType": "application/directory" },
"value": { "href": "https://eratosthenes.pvretano.com/Projects/radarsat/repository/RS2_OK95449_IK624299_PEK008698378_OSVN_20180315_222217_VV_VH_SCF/" }}
}
],
"outputs": [
{
"id": "output",
"transmissionMode": "reference"
}
],
"mode": "async",
"response": "document",
"repeat": "P1W"
}Triggered execution is a function of the notification module. A subscription is created for a specific event and if the even occurs, one of the notification methods can be process execution. For example, a user can subscribe to notified when new TEP-holding data is added to the TEP and specify that the notification method should be the execution of a specified process.
19.11. Results manager
Every application that executes on the TEP will generate some result(s). Processing results are always available via the OGC API - Processes - Part 1: Core interface via the `/jobs/{jobID}/results' endpoint. However, this interface only presents the raw results. In many cases it is desirable to publish results using an OGC API endpoint so that the results can be easily visualized or integrated with other results or other data.
How the ADES responds to a request is controlled by the response parameter in the execute request. The currently defines values for the response parameter are raw and document. The value raw indicates that the raw output generated by the process should be returned (e.g. a GeoTIFF image). The value document indicates that a JSON response document should be generated that contains all the outputs generated by a process. The output can be encoded in-line in the response document or referenced via a link.
For the CSA project, the schema of the execute request will be extended with a new parameter named publish as indicated in the following schema fragment:
type: object
properties:
inputs:
additionalProperties:
oneOf:
- $ref: "inlineOrRefData.yaml"
- type: array
items:
$ref: "inlineOrRefData.yaml"
outputs:
additionalProperties:
$ref: "output.yaml"
response:
type: string
enum:
- raw
- document
- publish
default:
- raw
endpoint:
type: string
format: uri
subscriber:
$ref: "subscriber.yaml"A value of publish for the response parameter will trigger the ADES to publish the results of processing to an OGC API endpoint. The value of the endpoint parameter is the URI of a collections to which processing results should be published. If the specified endpoint URI does not exist, the ADES will first create the endpoint before publishing the results.
20. Quotation and billing
20.1. Quotation
This section describes the quotation mechanism that extends capabilities of an OGC API - Processes service to estimate the resource requirements for executing a process, and the relevant costs that would result from allocating those resources to perform the actual process execution. The result from a quotation would provide an estimate of the expected amount that would be billed to the user for processing its operations if he deems the costs are acceptable to proceed with its execution.
Following sections will provide further context about quotation estimates, details about the operations implied by these new capabilities as well as presenting proposed implementation details.
20.1.1. Quotation Literature Review
State of the Art Review
Costs can be associated to allocated resources in order to perform a given task or workflow:
-
Computation costs: the number of individual CPUs allocated multiplied by the processing time. The type of processor may affect costs when, for instance, GPUs are used.
-
Storage costs: the storage volume allocated for staging the inputs and output products. The type of storage (fast or slow) may impact the cost structure also.
-
Communication costs: the cost of transferring the data in and out of the infrastructure.

A cloud data center is equipped with several physical machines or servers to offer on-demand services to the customers. Cloud provides dynamism, uncertainty and elasticity based services to users in pay-as-you-go fashion over the internet. In recent decades, increases in requests (diverse and complex applications) for cloud services is raising the workload in cloud environment. The applications are hosted in the form of virtual machines (VMs) that are placed on one or more servers. The resource utilization and the current state of the data center are monitored over time using a device called resource manager. The task of the resource manager is to assign the resources to the applications in an efficient manner, and predictive models help in achieving the same by providing an estimation of future workload. The predictive resource assignment schemes improve the economic growth of the service provider by maximizing the utilization and reducing electricity consumption.
In cloud computing, to optimize one or more scheduling objectives (e.g., makespan, computational cost, monetary cost, reliability, availability, resource utilization, response time, energy consumption, etc.), a scheduler (broker) is developed in order to determine potential solutions for allotting a set of available limited resources to incoming tasks/applications. Resource management becomes the prominent issue in cloud computing due to rapid growth of on-demand requests and heterogeneous nature of cloud resources. We can differentiate resource provisioning and resource scheduling as shown in the Figure below.
Inefficient scheduling techniques face the challenges of resources being overutilized and underutilized (imbalanced) which leads to either degradation in service performance (overutilization) or wastage of cloud resources (underutilization). The basic idea behind scheduling is to distribute tasks (of diverse and complex nature) among the cloud resources in such a manner that the scheduling algorithm avoids the problem of imbalance. The Scheduling algorithm should also optimize key performance indicator parameters like response time, makespan time, reliability, availability, energy consumption, cost, resource utilization, etc. To fulfill the above-mentioned objective, many state of art scheduling algorithms have been proposed based upon heuristic, meta-heuristic and hybrid, reported in the literature.
Effective resource scheduling not only executes the tasks in minimum time but also increases the resource utilization ratio, i.e. reduces the resource consumption. Scheduling of tasks becomes a matter of great concern due to continuous increases in workload for cloud data centers that may lead to the scarcity of cloud resources. Task scheduling is a key aspect of cloud computing, which strives to maximize Virtual Machines' (VMs') utilization while reducing the data centres' operational cost, which in turn reveals significant improvements in the Quality of Services (QoS) parameters and the overall performance.
Grid computing and cloud computing resources can provide an optimal solution that can meet the user’s requirements by providing scalable and flexible solutions for considered applications. The cloud computing based task scheduling differs from the grid computing based scheduling in the following two ways:
-
Resource sharing:
-
Cloud computing offers advanced services by sharing resources using the virtualization notion with the help of internet technologies. Consequently, it supports real-time allocation to fully utilize the available resources while improving elasticity of cloud services. Thus, the scheduler in a cloud workflow system needs to consider the virtualization infrastructure (e.g.:virtual services and virtual machines) to efficiently facilitate the computational processes.
-
In contrast, grid computing allows allocating a large cluster of resources in a shared mode. Therefore, it supports batch processing and resources will be available once they are released by other users.
-
-
Cost of resource usage:
-
Cloud computing provides a flexible costing mechanism in considering the user’s requirements (i.e.: pay-as-you-go and on-demand services).
-
On the other hand, grid computing follows a quota strategy to determine the accumulated cost of requested services.
-
Pricing schemes in cloud systems are based on lease intervals from the time of provisioning, even if the instance is only used for a fraction of that period. However, cost in Grid is calculated based on the accumulated cost of requested services. Launching too many instances does not lower makespan. Instead, it causes high scheduling overhead and low instance utilization. As one would expect, poor resource provisioning wastes available user budget.
Papers investigating Machine Learning techniques applied to resource management are mostly looking at predicting future workload at time t+1 from historical data (time series prediction) [1], [2], [3], [4]. Meta-heuristics such as Genetic Algorithm(GA), Ant Colony Optimization (ACO) and Particle Swarm Optimization (PSO) are used to tackle the workflow scheduling problem with multiple constraints [5]. In [7], a genetic algorithm approach was used to address scheduling optimization problems in workflow applications, based on two QoS constraints, deadline and budget.
Scientific Workflows Management
Scientific Workflow Applications (SWA) are the most widely used models for representing and managing complex distributed scientific computations [6]. A Directed Acyclic Graph (DAG), with atomic tasks (called steps in the quotation system) as vertices, is the most common abstraction of a workflow. The DAG is beneficial to highlight the estimated execution cost of different available resources based on the historical data of a system. The cost optimization challenge of Scientific Workflow Scheduling (SWS) in cloud is a NP-complete optimization problem and requires the consideration of three main aspects:
-
strong interdependencies between the SWA steps. This computational intensiveness of steps introduces complexity to the scheduling processes, since the data of the SWA steps needs to be transferred between the computational resources (i.e.: VMs) of cloud computing;
-
different sizes of SWA datasets that need to be considered by the scheduler, which significantly affect the execution time and execution cost. Thus, data intensiveness needs to be considered while calculating the completion time (makespan) and total cost of executing the steps of SWA on available resources (i.e.: VMs), and;
-
different numbers of computational resources (VMs) based on the user requirements.
Most studies on workflow scheduling assume that estimated execution time for workflow steps are known. Task runtimes can be estimated through analytical modelling, empirical modelling and historical data [8]. The Pegasus workflow generator [10] can create representative workflows with the same structure as five real world scientific workflows (Cybershake, Epigenomics, Montage, LIGO and SIPHT). Tools like CloudSim [11] can then simulate the workflow execution in a cloud infrastructure.
In the literature, cost optimization approaches of SWS have been proposed mainly focused at minimizing the total computational cost of SWS. In the literature, several approaches have been proposed for cost optimization challenge of SWS by employing different types of approaches, e.g., heuristic, meta-heuristic. More details about the existing cost optimization taxonomies and approaches for SWS in cloud computing environment can be found in some recent review papers [7], [8].
*Potential Design for the Quote Estimation System for Scientific Workflows*
A preliminary design for the quote estimation system could be the following:
-
Profiling of individual atomic processing steps available in SNAP Sentinel-1 toolbox [9]: the goal is to collect basic processing information about each individual task execution (Makespan, storage requirements, etc.) for different inputs, parameter values and VM types. Some parameter values can have a significant impact on processing times (ex: spatial resolution in meters). Note that each of the individual tasks must start by one or several read operations as well as at least one write operation. The time overhead related to the start of the VM must be allocated also;
-
Generate a set of SWFs from available atomic steps: it can include default SWFs available within SNAP as well as random combination of atomic steps. The writing of temporary files between steps may also impact processing time;
-
Profiling of SWFs: same as point 1 above but indicate where parallel steps can be run as it will impact costs.
-
*Represent SWFs as a DAG: each vertex will include features about individual steps (process and input metadata);
-
Run Machine Learning techniques to infer costs from collected DAGs: the input is the DAG and the target is the total cost. ML technique could be a Graph Neural Network trained for a regression task;
-
Continuous learning: during operations, the SWS can accumulate historical data that can be exploited to refine the quote estimation model by updating the Process Metadata object of the Quotation System (See Quote submission, estimation and description operations.).
20.1.2. Quotation Operations
Most of the methodologies employed by the Quotation extension are inspired from
OGC API - Processes: Core operations regarding the
execution of a process. In other words, all asynchronous and synchronous execution mechanism, control parameters to
select the execution mode, and any status monitoring methodologies would be implemented using the same definitions
as for the /processes/{processID}/execution endpoint. Instead of executing the process directly, its quote
estimation would be requested instead using a POST toward the /processes/{processID}/quotations endpoint, as
presented in the following figure. Submission of this quote request is accomplished using the same inputs and
outputs parameters as normal execution in order to adapt the estimated quote to the specific parameters for the process.

The figure presents how the OGC API - Processes service could be defined in such as way to allow the reception of multiple quotation requests, which would be then handled over time by a task processing queue. Those tasks would then gradually accomplish the quote estimation, potentially in parallel according to the available amount of working unit for this purpose, using the submitted inputs, outputs and the reference process. The estimator could then employ any relevant data sources, process metadata, heuristics, business logic, and so on to provide the best possible estimation of the process considering the provided inputs and desired outputs. The proposed and presented architecture is separated between the Web Service and the Quotation System portions since these components could be running on distinct machines, or have access to entirely different resources, due to their contrasting nature. Effectively, the Web Service should be geared toward higher servicing capabilities to handle more parallel user requests (including non quotation ones), while the Quotation System could take advantage of hardware capabilities to process estimations, using for example Machine Learning or other algorithms with heavier computing requirements.
Once quote estimation has completed, either asynchronously or synchronously, the detailed quotation can be obtained.
A GET request on the /quotations/{quoteID} endpoint is employed for this purpose, mimicking the /jobs/{jobId}
endpoint that is used in Core, to retrieve the execution status of a process. In this case, the quotation endpoint
is used to monitor the active quote evaluation by the Quotation System, and retrieve the final quote once it has
been processed entirely.
20.1.3. Quotation Schema
The main schema quote.yaml represent the completed quote description following the full quotation estimation operation has been successfully accomplished. This content contains metadata about the quoted process as well as details related to estimated execution costs and currency, the estimated execution duration, and other control parameters to manage this quote by the system. The values represented by this schema entirely depend on the applied estimation methodology, which is left open to implementers as it depends on a combination of processing capabilities of each infrastructure, business rules and other external factors.
The detailed quote schema is separated into two components,
namely quotePartial.yaml
and quoteDetails.yaml because the completed quote with all relevant
details will not be available until the estimation has completed, which might take more or less time based on the number
of requests the server must process, business logic priorities, or the complexity of the process execution to be
estimated. Until the quote has finished estimation, the partial schema is employed to represent the submitted details
and the active status. This status can be employed to retrieve information about the quotation operation asynchronously
to its evaluation. On submission, the partial quote should be marked with submitted status and receive the creation
time. When the estimation engine starts processing the quote, it should be updated to estimating status.
Once estimation is completed, the partial quote is expected to be updated with relevant metadata to a detailed quote
and the completed status. In case of error, failed status should be set instead. A completed quote should always
be reported by the quotation endpoint using quote.yaml schema.
The quotePartial.yaml is employed instead for any other status.
Because it is possible that a process could be the result of multiple underlying process executions, whether from
dispatching those executions from the EMS to one or more ADES, by instantiating OGC Application Packages
or simply by defining a workflow processing chain using other OGC API - Processes extensions such as
Part 2
Deploy, Replace, Undeploy (DRU) or
Part 3: Workflows, each quote can
optionally contain a stepQuotationList.yaml definition. If the
Quotation System needs to estimate multiple sub-quotes that would better describe the complete workflow quote,
individual step quotes can be listed under the steps field. Each of those item is an identical representation to
the final quoteDetails.yaml, allowing a nested representations as to detail
individual steps as much as needed, while leaving flexibility in the representation.
In order to summarize the final quote, parent quotes that nest further sub-quotes should provide the total
as the sum of all nested prices. Similarly, estimated durations should also be provided for the complete quote.
As mentioned previously, quotation requests are accomplished using the same payload and parameters as a normal
process execution request. Below is a sample content of the quotation request body that could be submitted to a
process that takes a single JSON file input, and produces a modified output_file.
{
"inputs": {
"file": {
"href": "https://ogc-ems.crim.ca/wps-outputs/example-nc-array.json",
"type": "application/json"
}
},
"outputs": {
"output_file": {
"transmissionMode": "reference"
}
}
}Given this content was POSTed on the quotation endpoint with asynchronous preference headers, a quote estimation task would be registered in the system. The following sample representation of the response contents would be returned in order to accomplish later status evaluation.
{
"id": "8deed2af-651e-40ef-8b0d-f54925d21192",
"processID": "docker-demo-cat",
"status": "submitted",
"created": "2022-02-18T22:48:45.581000+00:00",
"expire": "2022-02-19T22:48:45.581000+00:00"
}Following sufficient polling, an after passing through the estimating state by being evaluated by
the Quotation System, would eventually reach the completed status. Requesting the status endpoint once again would
finally yield a result similar to the following sample content.
{
"quoteID": "88a6abc6-a8c6-46f8-87a5-289fb073df03",
"processID": "docker-demo-cat",
"status": "completed",
"detail": "Quote processing complete.",
"total": 123.45,
"price": 123.45,
"currency": "CAD",
"created": "2022-02-18T22:48:45.581000+00:00",
"expire": "2022-02-19T22:48:45.581000+00:00",
"userID": "1a6ebe22-0dd4-4e21-87f5-071690eefca3",
"estimatedTime": "00:02:03",
"estimatedSeconds": 123,
"estimatedDuration": "PT02M03S",
"processParameters": {
"inputs": {
"file": {
"href": "https://ogc-ems.crim.ca/wps-outputs/example-nc-array.json",
"type": "application/json"
}
},
"outputs": {
"output_file": {
"transmissionMode": "reference"
}
}
}
}As it can be seen above, the execution inputs, outputs, and any other metadata deemed necessary to reproduce the
execution is saved within the quote, allowing later reference.
20.2. Billing
Because every submitted quotation request for a given process contains all the necessary details to run this process,
it is possible to employ the provided contents directly to request its execution. For convenience, the request endpoint
/quotations/{quoteID}/execution is used to POST the details stored as
processExecuteParameters.yaml since they contain the
corresponding fields required for fulfilling the typical
execute.yaml
request contents.
In addition than for convenience purposes, this also guarantees that the process that would be executed through
the quotation mechanism will match with the estimated quote results, as the exact same parameters would be submitted
for execution. This reduces chances of manipulation errors in contrast to relying on an external entity that would
otherwise have to extract the contents themselves from the quote and supply them accordingly without alteration in a
subsequent request for execution on the /processes/{processID}/execution endpoint.
This would produce unnecessary data handling steps that can be avoided, as well leaving opportunities to falsify the
information of the originally estimated quote. Using the parameters already stored in the quote definition, this
alleviates these issues.
The last and most important advantage of this endpoint is that it allows triggering the billing mechanism, which is
further detailed below.

As presented in the figure, most of the billing operations first consist of extracting the relevant execution parameters from the submitted quote, and then proceed to the usual execution of the process using them. One additional step required prior to the process execution is the evaluation of the user profile which requests this execution. Effectively, because someone, or an organization, will have to be billed for allocating the necessary resources to execute the estimated process requirements with the quote, the user must be identified. This identification mechanism could be implemented with various methods, and is therefore left open to the decision of the service provider. It is generally recommended to employ traditional HTTP authentication (RFC-7235) or OAuth (RFC-6749) techniques to facilitate interactions with web services using well known identity resolution approaches. Once identity has been resolved, it should be carried over along with the process execution parameters to run the process, resulting in a job (as per OGC API - Processes: Core) to monitor and obtain execution status information.
Following process execution, the task handling the job being processed can proceed to additional steps involved specifically for the billing operations. One optional step to consider accomplishing here is to collect metadata about real execution parameters and allocated resources by the job in order to better estimate future quote submissions. The Quotation System could then take advantage of better use-case metadata to improve its estimation algorithm. Using the quote details retrieved at the start of the billing process, such as the estimated total and currency information, the bill can then be created and charged to the identified user. The intricate details about the billing process itself, such as retrieving account holder data and sending transaction information toward a financial institution are omitted to simplify the figure, but would be involved during this step.
Finally, after successfully billing the customer for the execution of the process, the job results are published.
More specifically, the outputs generated by the process execution are made available to the user using the
relevant delivery system selected by the platform hosting the service. This would be done through a catalogue or simply
a file server accessible by an URL inscribed along with the job details.
Results are updated only after billing was validated to ensure that, even when running the process asynchronously, it
is not possible to obtain them in advance when monitoring the job status information endpoint.
After job completion, either synchronously or asynchronously, the typical /jobs/{jobId}/results endpoint from
OGC API - Processes: Core can then be used to retrieve the outputs the user paid for.
In order to track bills created by these operations, it is recommended to store billing metadata using the schema
defined in bill.yaml. This definition should minimally contain details regarding
the associated quote ID, the executed process ID, the job that processed it to link to the relevant outputs, and a
user identification reference that was billed. Furthermore, the billed price and currency, as well as the date the
billed was charged should be tracked in the billed. Any additional details that jugged necessary for tracking billing
by the system can also be added. Because billing can contain sensitive data, such as the user details, it is not
strictly required to expose this information through API endpoints. A protected API could still provide this
information, using for example a GET request to /bills/{billID} to retrieve this data for management purposes.
The following sample contents provide an example of what a bill could look like using the specified schema.
{
"billID": "10515b5e-f696-4bab-a0f0-e5f54cbfdf87",
"quoteID": "88a6abc6-a8c6-46f8-87a5-289fb073df03",
"jobID": "9055cc7c-d2d7-4b4d-b7b6-51252b608c08",
"processID": "docker-demo-cat",
"userID": "1a6ebe22-0dd4-4e21-87f5-071690eefca3",
"price": 123.45,
"currency": "CAD",
"created": "2022-02-19T10:36:27.492000+00:00"
}21. TEP Marketplace Web Client
The TEP Marketplace Web Client is the public face of the application. It handles all interactions with the TEP, whether from developers wishing to publish applications or users needing to run those applications on cloud hosted data. It will be implemented using a modern, responsive toolkit (Bootstrap 4 - https://getbootstrap.com/) that uses a “mobile-first” philosophy, to insure maximum flexibility across a variety of devices.
Responsive applications automatically adjust their interfaces to best suit the displaying device, in order to present the best user experience.
21.1. Modes of Operation
The EMS Client supports several modes of operation that are automatically set depending on the credentials available to a user when they log in. These may be implemented as subsets of each other, i.e. Developer Mode may include all the functionality of User Mode, plus the Developer-only portions, etc.
21.1.1. Developer Mode
Developer mode allows the uploading and registration of image processing applications for execution in the cloud provider’s infrastructure. The Client will present the developer with a nicely formatted set of forms to describe their application and perform the registration.
A view on the catalogue is also presented to customers, so that they can browse and manage the applications they have uploaded, and view applications uploaded by others (subject to access control restrictions). Developers will be able to query statistics collected on their applications, such as the number of times they have been executed, and by whom, etc.
21.1.2. User Mode
User mode is the more complicated version of the Web Client. It provides a catalogue interface, similar to the developer’s view, so that the user can search for applications that he/she wishes to execute. But it also provides full search capabilities on the catalogue of available data (subject to access control restrictions), using a map interface to define areas of interest, and various filters to request data with specific characteristics, such as percent cloud cover, etc.
The user can use this screen to select a set of data for processing, and an application that he/she wishes to execute on it.
User mode provides a status and reporting screen, where the user can monitor the status of running jobs and view the results of completed ones.
21.1.3. Admin Mode
Depending on implementation details, the Web Client may also provide an administrator’s mode, where users with the requisite admin privileges can take care of various system administration and house-keeping tasks, such as managing the catalogue, registering new data, cleanup of old computation results etc. As with the other modes, this mode is automatically available (or not) depending on the user’s credentials.
22. Storage layer
All TEP data is managed in the storage layer.
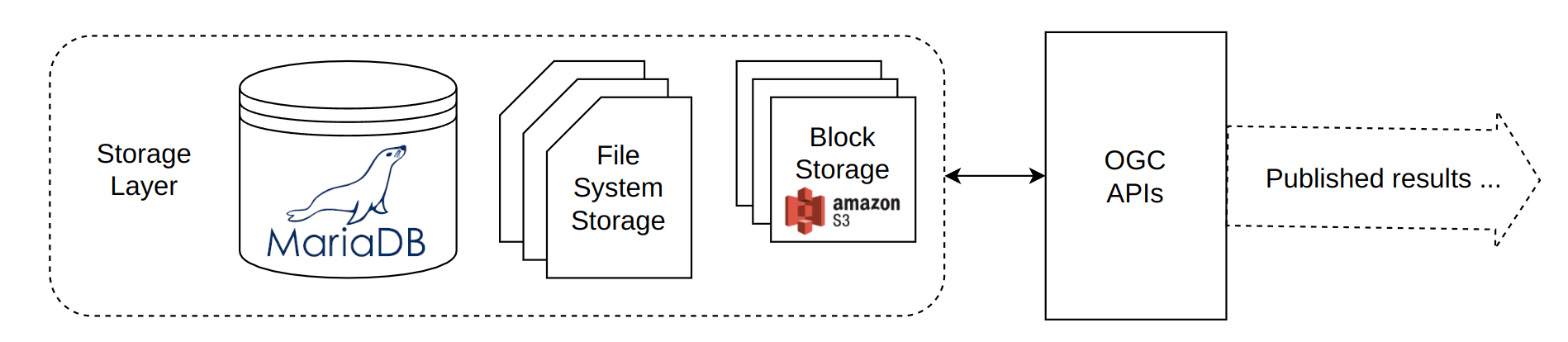 Figure 2 - TEP Storage Layer
Figure 2 - TEP Storage Layer
The following categories of data are managed in the storage layer:
-
TEP-holdings
-
Data that the TEP offers to all users such as RCM or Sentinel-1 data.
-
-
User’s TEP workspace data
-
Data that a user has uploaded to the TEP or has been generated as a result of processing initiated by the user.
-
-
Derived data
-
Derived data is data that has been loaded into CubeWerx Suite and is accessible via an OGC API. The source data, from which the derived data is produced, is the TEP-holdings and/or the user’s TEP workspace data.
-
-
Product data
-
These are the files of CubeWerx Suite itself and includes executables, CubeWerx Suite libraries, 3rd-party libraries, configuration files, etc.
-
-
Temporary data
-
Data that is temporary such as data staged-in by the ADES for processing.
-
The TEP’s storage layer is composed of the following components:
-
a MariaDB database
-
file system storage (either locally or network mounted file systems)
-
an S3 object store
TEP-holdings are stored in S3. User’s TEP workspace data is also stored in S3 as are any processing results. Derived data (e.g. map tiles, data tiles, etc.) are stored in MariaDB. Product data and temporary data are stored as files on mounted file systems.
Annex A: Revision History
| Date | Release | Editor | Primary clauses modified | Description |
|---|---|---|---|---|
2016-04-28 |
0.1 |
G. Editor |
all |
initial version |
Annex B: Bibliography
[1] Journal: Al-Asaly, M., Bencherif, M., Alsanad, A., & Hassan, M.: A deep learning-based resource usage prediction model for resource provisioning in an autonomic cloud computing environment. Neural Computing and Applications, 1–18. (2021).
[2] Journal: Kumar, J., Singh, A. K. & Buyya, R.: Self directed learning based workload forecasting model for cloud resource management. Inform Sciences 543, 345–366 (2021).
[3] Journal: Houssein, E. H., Gad, A. G., Wazery, Y. M. & Suganthan, P. N.: Task Scheduling in Cloud Computing based on Meta-heuristics: Review, Taxonomy, Open Challenges, and Future Trends. Swarm Evol Comput 62, 100841 (2021).
[4] Journal: Kaur, G., Bala, A., & Chana, I.: An intelligent regressive ensemble approach for predicting resource usage in cloud computing. Journal of Parallel and Distributed Computing, 123, 1–12. (2019).
[5] Journal: Mason, K., Duggan, M., Barrett, E., Duggan, J., & Howley, E.: Predicting host CPU utilization in the cloud using evolutionary neural networks. Future Generation Computer Systems, 86, 162–173. (2018).
[6] Journal: J. Taylor, E. Deelman, D. B.: Gannon, and M. Shields,: Workflows for e-Science: Scientific Workflows for Grids. New York, NW, USA: Springer Publishing Company, Incorporated, (2014).
[7] Journal: Alkhanak, E.N., Lee, S.P., Rezaei, R., Parizi, R. M.: Cost optimization approaches for scientific workflow scheduling in cloud and grid computing: A review, classifications, and open issues, J Syst Software, vol. 113, pp. 1–26, (2016).
[8] Journal: Alkhanak, E.N., Lee, S.P., Khan, S.U.R.: Cost-aware challenges for workflow scheduling approaches in cloud computing environments: Taxonomy and opportunities, Future Generation Computer Systems (2015),
[9] Journal: Veci, L., Lu, J., Foumelis, M., & Engdahl, M.: ESA’s Multi-mission Sentinel-1 Toolbox. In EGU General Assembly Conference Abstracts (p. 19398). (2017, April).
[10] Web: The Pegasus Project: Workflow examples, https://pegasus.isi.edu/documentation/examples/
[11] Web: Singh, A.: CloudSim Simulation Toolkit: An Introduction, https://www.cloudsimtutorials.online/cloudsim-simulation-toolkit-an-introduction/